今回は「ミックスボイスとは何なの?」という部分に焦点を当てた内容です。
ミックスボイスという言葉は、人によってその定義・解釈が様々で、最も混乱しやすい言葉だと言えます。
なので、ミックスボイスの語源や定義などをしっかりと整理して、その上でどう考えるべきか?というのが今回のテーマです。
目次
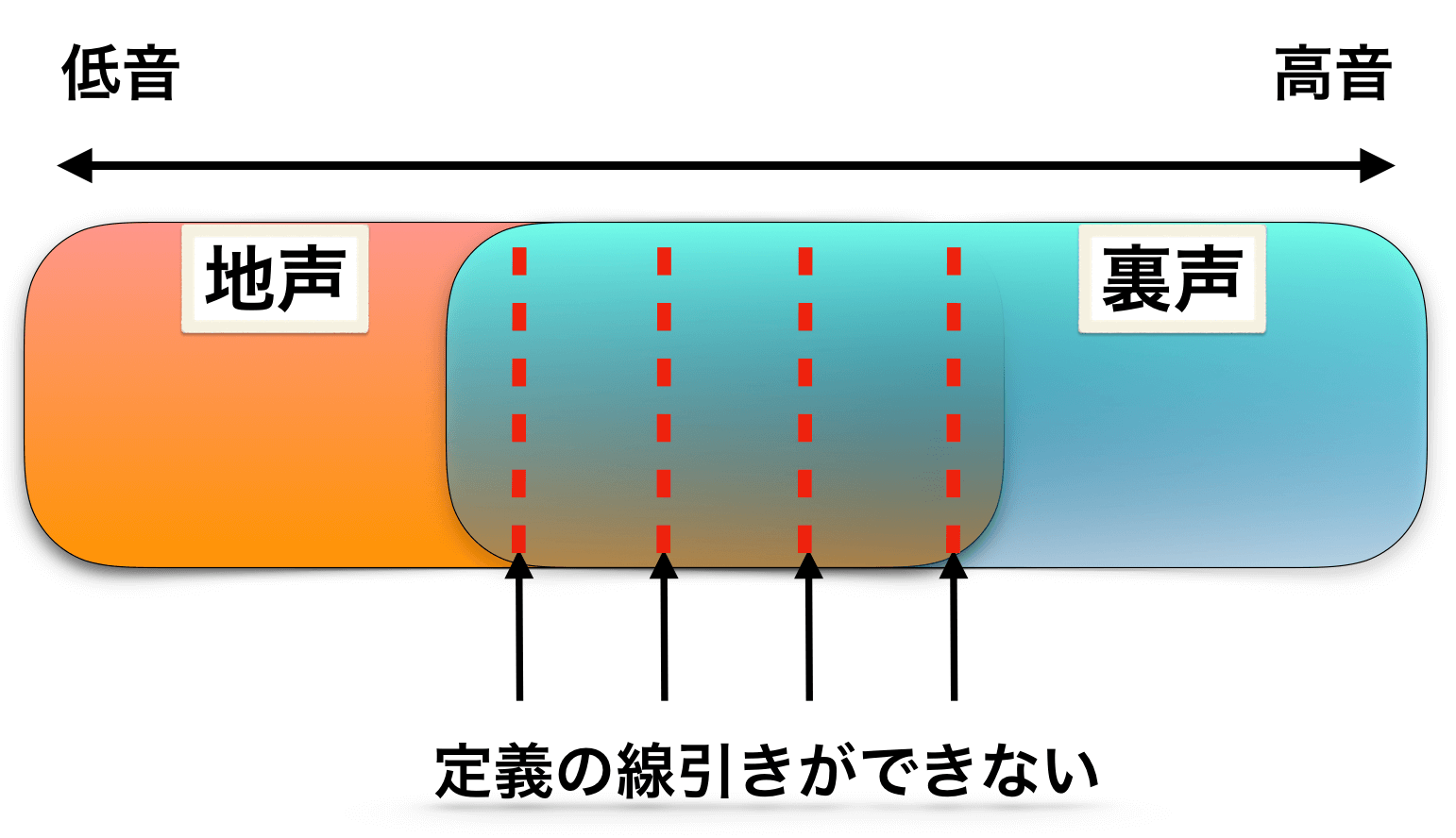
ミックスボイスは”音声学における声区としては”存在しない
まず、音声学における声区(vocal register)の区分上、ミックスボイスという声区は存在しないと考えるのが定説です。
あえて強調しますが、『声区は』です。
声区とは、
声帯の機能区分のことで、「地声」「裏声」のように声帯のモードが切り替わる区分のことです。
「①声帯の振動パターン」「②一連のピッチ」「③音の種類」という3つの要素によって決まるとされています。
1970年代、音声専門家の国際組織である『the Collegium Medicorum Theatri (CoMeT)』によって声区は4つに定義され、それが現在の音声学的な基本の考え方となっています。
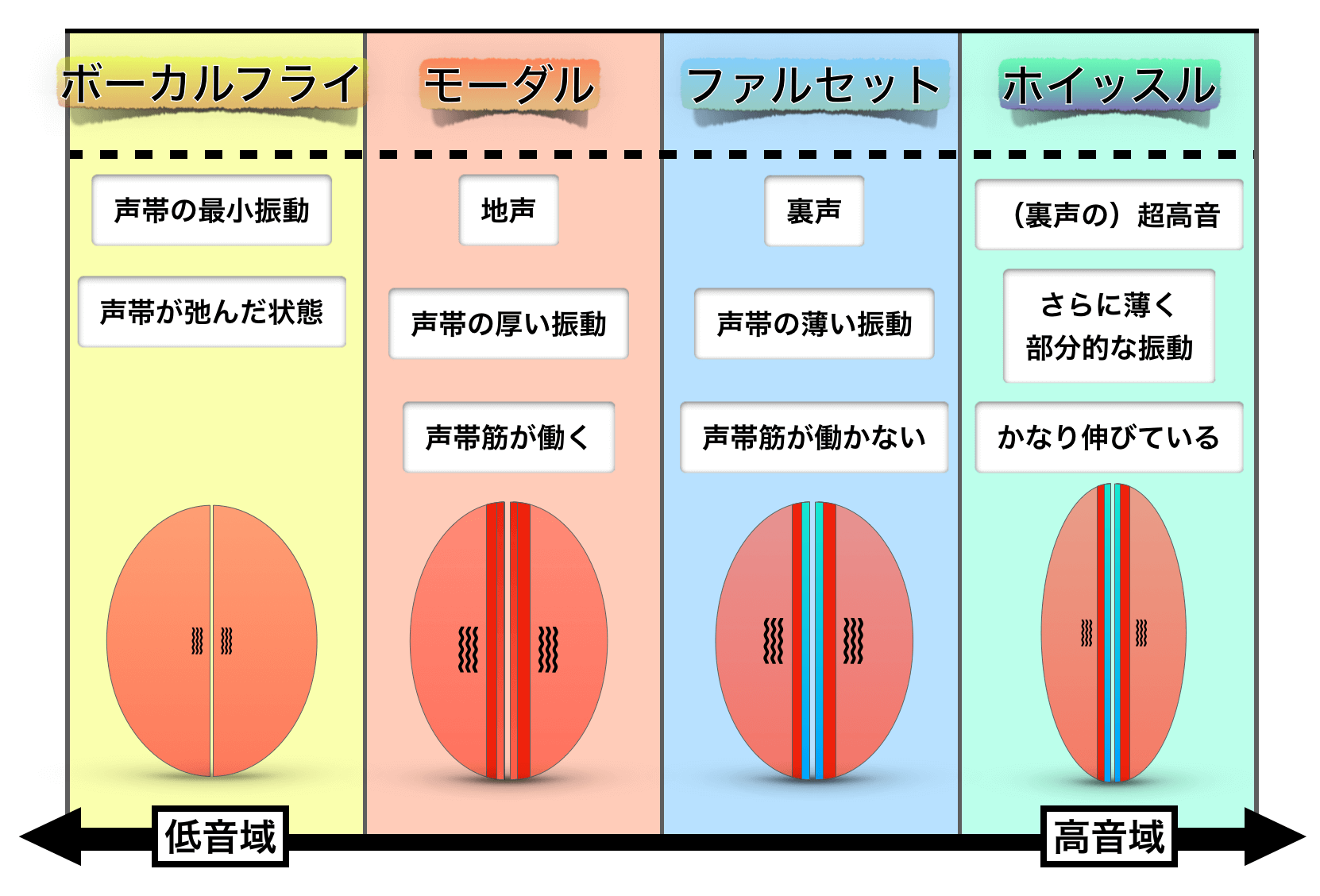
それぞれ、
- ボーカルフライ(エッジボイス)
- モーダル(地声)
- ファルセット(裏声)
- ホイッスル
という4つに定義されています。
「なんか変じゃない?」と感じるかもしれませんが、声区を決めるルールに基づいて分類された音声学的分類なので、こういうものだと受け入れるしかありません。
当時、『モーダルとファルセットの中間』についても議論されたようですが、結局定義するには至らなかったとされています。
つまり、音声学的にはミックスボイスを区分できなかったのですね。
実際、歌っている本人がどれだけ中間的な感覚を持っていたとしても、声区としては必ず「地声」か「裏声」で区分できる、という論文があります↓
From a physiological point of view, two main laryngeal vibratory mechanisms, M1 and M2, are used successively from the bottom to the top of the vocal range. From a musical point of view, singers distinguish many registers, most of which rely on resonance adjustements. Voix mixte, which is related to the area of overlap of M1 and M2, is a register found in different voice categories.
The present study on French voix mixte, carried out with 5 professional singers of both sexes, shows, on the basis of glottal open quotient (Oq) measurements, that voix mixte is not related to a different, or "mixed", laryngeal mechanism.
Voix mixte sounds are always clearly produced in a given laryngeal mechanism, M1 or M2.
訳)生理学的な観点から、2 つの主要な喉頭振動メカニズム、M1(地声) と M2(裏声) は、声域の下から上に向かって連続して使用されます。 音楽的な観点から、歌手は多くの音域を区別しますが、そのほとんどは共鳴調整に依存しています。 M1 と M2 の重なり合った領域に関連する Voix mixte (ミックスボイス)は、異なる種類の声として見られています。
フランスの voix mixte (ミックスボイス)に関する現在の研究は、男女の 5 人のプロの歌手で行われ、声門開口商 (Oq) 測定に基づくと、voix mixte は喉のメカニズムとして『(地声・裏声とは)異なるもの』『混合されたもの』ではない(関連性がない)ことが示されています。
Voix mixte(ミックスボイス)の音は、 M1(地声)か M2(裏声)のどちらかのメカニズムによって常に明確に生み出されています。//
つまり、いくら中間的な感覚を持っていたとしても、それはあくまでも本人の感覚(共鳴調整)の区分でしかない。厳密に調べれば、必ず地声か裏声に分類できるということですね。
実際、英語圏では「声区ではない」という考え方は意外と主流?
日本では、ミックスボイスを『地声と裏声の中間にある声区』的な扱いをすることが多いですが、英語圏ではミックスボイスを声区として扱っていないことが多いです。
実際、アメリカ版のGoogleで「What is mixed voice?」と検索すると、以下のサイトが上位に出てきます↓
Mix voice is NOT a mixture of 'Head' and 'Chest'. Neither is it a separate vocal register. Mix is a technique used in the middle of the range to disguise the transition from one vocal mechanism to another.
It is always produced in one or other of the main vocal mechanisms. It is, essentially, an acoustic illusion which can render the mechanism change inaudible.
訳)ミックス ボイスは、「頭声(裏声)」と「胸声(地声)」を混ぜたものではありません。また、独立した声区でもありません。ミックスとは、ある発声メカニズムから別の発声メカニズムへの移行を隠すために、中音域で使用されるテクニックです。
常に、主要な発声メカニズム(地声か裏声)のいずれかで生成されます。本質的には、メカニズムの変化を聞こえなくする音響的錯覚です。//
What is Mixed Voice? Mixed voice is when you combine your head voice and chest voice to create an even singing tone from the bottom to the top of your voice.
Some Common Misconceptions
Most teachers present mixed voice as just that: mixing head and chest voices into a single sound.For most practical intents and purposes, that’s a fine definition.
However, this is a bit of an oversimplification.
Chest and head voice both use different vibration patterns in the vocal cords.That’s why you can’t sing with both low and high cords at the same time.So in order to truly understand mixed voice, we have to talk about the vocal cords…
訳)ミックスボイスとは何? ミックスボイスとは、裏声と地声を組み合わせて、声の低音から高音まで均一な歌声を作り出すことです。
よくある誤解。多くの先生は、ミックスボイスを「地声と裏声を混ぜて一つの音にすること」と説明しています。ほとんどの実用的な目的には、それは素晴らしい定義です。
しかし、これは少し単純化しすぎです。
地声と裏声では、声帯の振動パターンが異なるのです。だから、低い声帯(地声)と高い声帯(裏声)を同時に使って歌うことはできないのです。
ですから、ミックスボイスを真に理解するためには、声帯の話をしなければならないのです...。//
It exists, if what you're referring to is the resonant placement or formant shifting. However, mix voice becomes a problem when coaches or people start referring to mix voice as if it was a completely new register separate from chest or head.
訳)共鳴の配置やフォルマントの移動のことを指しているのであれば、それは存在します。しかし、コーチや人々がミックスボイスを、胸(地声)や頭(裏声)とは別の全く新しい音域であるかのように言い始めると、ミックスボイスは問題になります。//
上位に限らず、多くのサイトが「声区ではない。間違いやすいですが、違いますよ。」と表現しています。
もちろん、Google検索の上位に出てくるからと言って、それが絶対に正しいものだとは限らないのですが、上位に出てくるということは、多くの人のミックスボイスの概念に影響を与えているでしょう。
つまり、ミックスボイスという言葉はあったとしても、それは地声と裏声の間にある”声区”という意味合いの言葉として使われるものではないのです。
では、どういう意味で使われているのか?
ミックスボイスの語源は『声区融合』
「英語圏でのミックスボイスが主にどういう意味で使われているか?」というのは、ミックスボイスの語源を知ると理解できます。
『ミックスボイス(mixed voice)』という言葉の由来は、フランス語『ヴォワ・ミクスト(voix mixte)』を英語に変換した時に生まれたものとされています。
このヴォワ・ミクストは
- 地声と裏声を境目がわからないくらい滑らかに繋げること
- もしくは、それを得るためのトレーニングや技術、能力の総称
を意味した言葉です。
つまり、先ほどの引用におけるミックスボイスもこのような意味で使われています。
日本語ではこれを「声区融合」と呼ぶことが多いです。
この『ヴォワ・ミクスト=ミックスボイス=声区融合』は、特定の発声名を指しているものではなく、「地声と裏声が綺麗につながっている」という『状態』や『結果』を表しています。
例えば、以下の二つの文章はほぼ同じ意味になります。
- 「次のフレーズは、地声から裏声まで境目がわからないように上手く繋げて。」
- 「次のフレーズは、上手くミックスボイスを使って。」
他にも、
- 「君は地声から裏声までとても滑らかに繋がっているね」
- 「君はとても良いミックスボイスを持っているね」
という感じです。
日本語では、この解釈をしにくい
おそらく、上記の意味では「日本のミックスボイスと全然違うじゃん。」と考える人もいるでしょう。
それはその通りで、日本ではざっくり言えば『地声と裏声の間にある声区』、もしくは『裏声ではない高い声(地声のように聞こえる高い声)』をミックスボイスとする考え方が多いです。
つまり、発声名そのものを指しています。
もちろん、英語圏でもこの考え方をする人はいるので、先ほどの引用でも常々「ミックスボイスは声区ではないですよ」と注意喚起が書かれてはいます。
ただ、日本では声区や発声を表す傾向が強くなりやすいと考えられます。
おそらくこれは、言語の問題です。
というのも、ミックスボイスという言葉は、英語ではミクストボイス(mixed voice)と表記されますが、日本語ではミックスボイス(mix voice)として広まってしまっていますよね。
この過去分詞(ed)があるかないかは、日本人的にはどうでもいい感じがしますが、英語的にはそこにちゃんと意味があります。
「mixed voice」だと、過去分詞によって「混ぜられた声」という状態や結果を表す表現になります。
- chest voice:「名詞+名詞」の複合名詞= 発声名を表している
- head voice:「名詞+名詞」の複合名詞=発声名を表している
- mixed voice:「過去分詞+名詞」の形容詞的用法=状態や結果を表している
というように文法上のニュアンスが違うのですね。
日本語の感覚に例えると、上二つは『混ぜご飯』みたいな名称を表しているニュアンスです。しかし、過去分詞の方は『混ぜられたご飯』という感じです。
「混ぜご飯作って」と言われると、『混ぜご飯』というメニュー名を作ればいいと解釈するが、「混ぜられたご飯作って」と言われると、なんだそれ?となりますよね。他にも「冷凍食品」と「冷凍された食品」、「焼き魚」と「焼かれた魚」などのような違いです。
つまり、「mixed voice」は過去分詞があることによって、「混ぜられたご飯」「冷凍された食品」「焼かれた魚」と同じように、名称ではなく状態を表しているニュアンスになるのです。
ちなみに、フランス語のvoix mixteも「名詞+形容詞」という構造。
英語は過去分詞の形容詞的用法、フランス語は単に形容詞、どちらも形容詞によって名詞を修飾し、状態や性質を表しているものです。
なので、mixed voiceが声区融合だと説明されれば「なるほど、地声と裏声を綺麗に繋げる状態を作ればいいのね。」と納得しやすいのでしょう。
日本人だって、「混ぜられたご飯というのは、ご飯をしゃもじでかき混ぜればいいんだよ」と言われたら納得できるはずです。
しかし、
英語にした途端に、日本人には「ミックスボイス(mix voice)」だろうが「ミクストボイス(mixed voice)」だろうが、発声名を表す一つの複合名詞のようにしか見えません。
「チェストボイス」や「ヘッドボイス」が発声名を表すのだから、「〇〇ボイス」と名前がつけば発声名を表しているものだと感じてしまうのは、ある意味当然です。 しかも、「mix voice」として伝わってしまっていて、過去分詞が消えているので、もはや完全に名詞扱いです。
この過去分詞の有無によって、考え方のズレが生じやすいのだろう考えられます。
「ミックスボイス」の定義を8パターンに分けて掘り下げてみる
ミックスボイスの本来の意味がどうであれ、この言葉は様々な解釈が広がり、もはや収拾がつかない状態だと言えます。
要は、多くの人に通じる一つの意味の言葉としては使えないのですね。
なので、ここからは「具体的にミックスボイスはどういう定義で使われるか?」を掘り下げていきます。
一般的には、以下の定義の一つ、もしくはいくつかを合わせたものであることが多いです。
- 地声と裏声を滑らかに繋げられる状態(声区融合)
- 地声と裏声を感覚的に混ぜる発声
- 地声の高音発声
- 裏声の低音発声
- 地声と裏声の中間的な声質の発声
- 共鳴位置が中間にある地声
- 共鳴位置が中間にある裏声
- 地声と裏声の間を埋める発声方法(=間にある声区)
日本で特に多そうなのは、②③⑧。
個人的にも、以前は②と③を複合したようなものだとざっくりと認識していました。
しかし、深く突き詰めれば、語源となった①以外は、どこかしらにツッコミようがあったり、定義にほころびがあります。
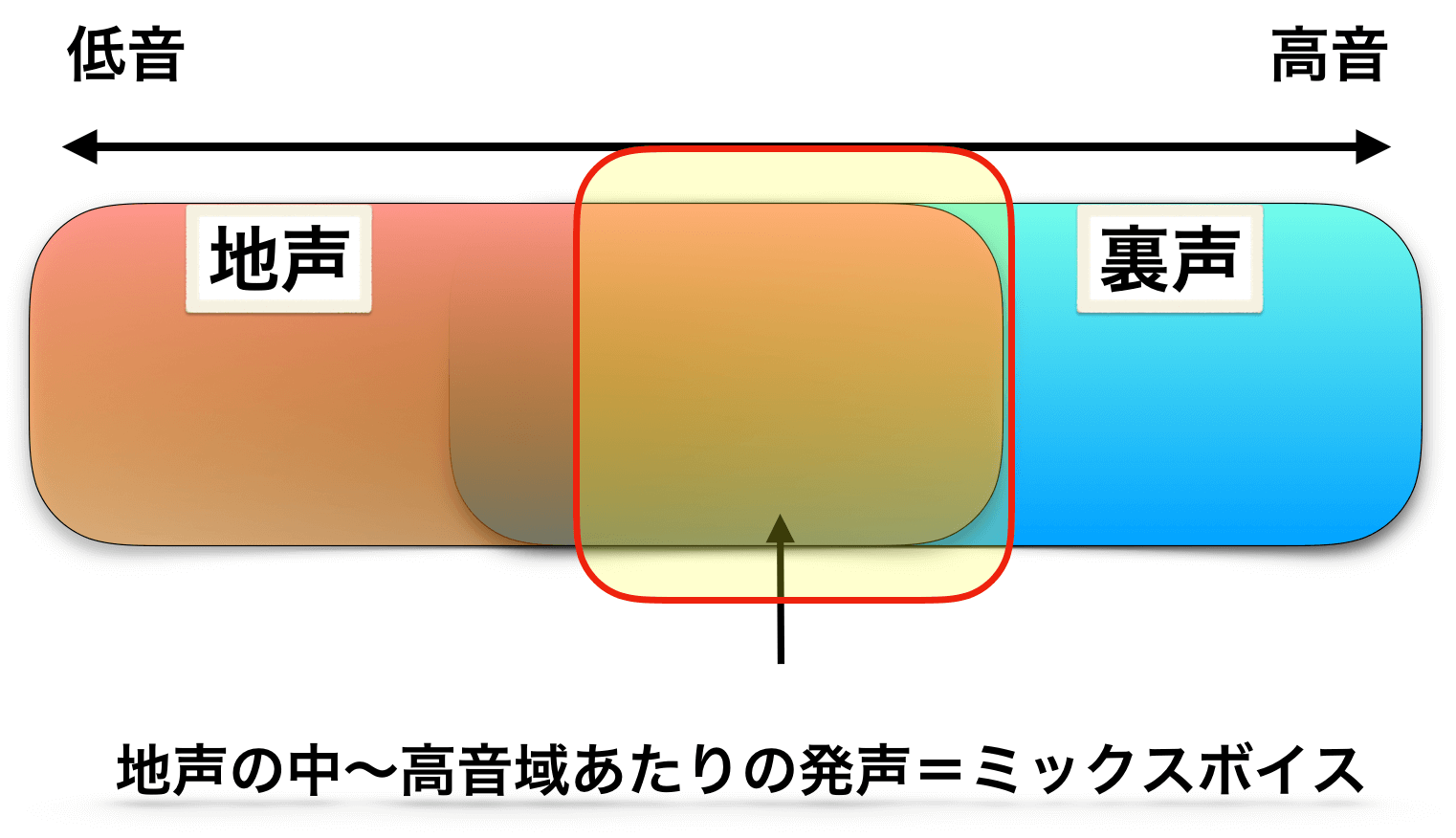
①地声と裏声を滑らかに繋げられる状態(声区融合)

先ほど述べたように、『声区融合できている状態』『地声から裏声までを途切れなくスムーズに切り替えることができる状態』もしくは、これらを実現させるためのトレーニングや技術、能力の総称をミックスボイスと呼ぶパターンです。
例えば、こんなイメージです↓
地声から裏声までを綺麗に移行していますね。これがミックスボイス(mixed voice)という状態ということです。
このように、自由自在に(自然に)地声と裏声を一本の声のように繋げるには、地声と裏声の両方のコントロール能力が必要になります。
例えば、地声から裏声へと移行する際に、
- 地声エネルギーを(100%→80%→40%→0%)とだんだん下げていく
- 裏声エネルギーを(0%→40%→80%→100%)とだんだん上げていく
というような力の受け渡しが上手く行われることで、綺麗に繋がります。
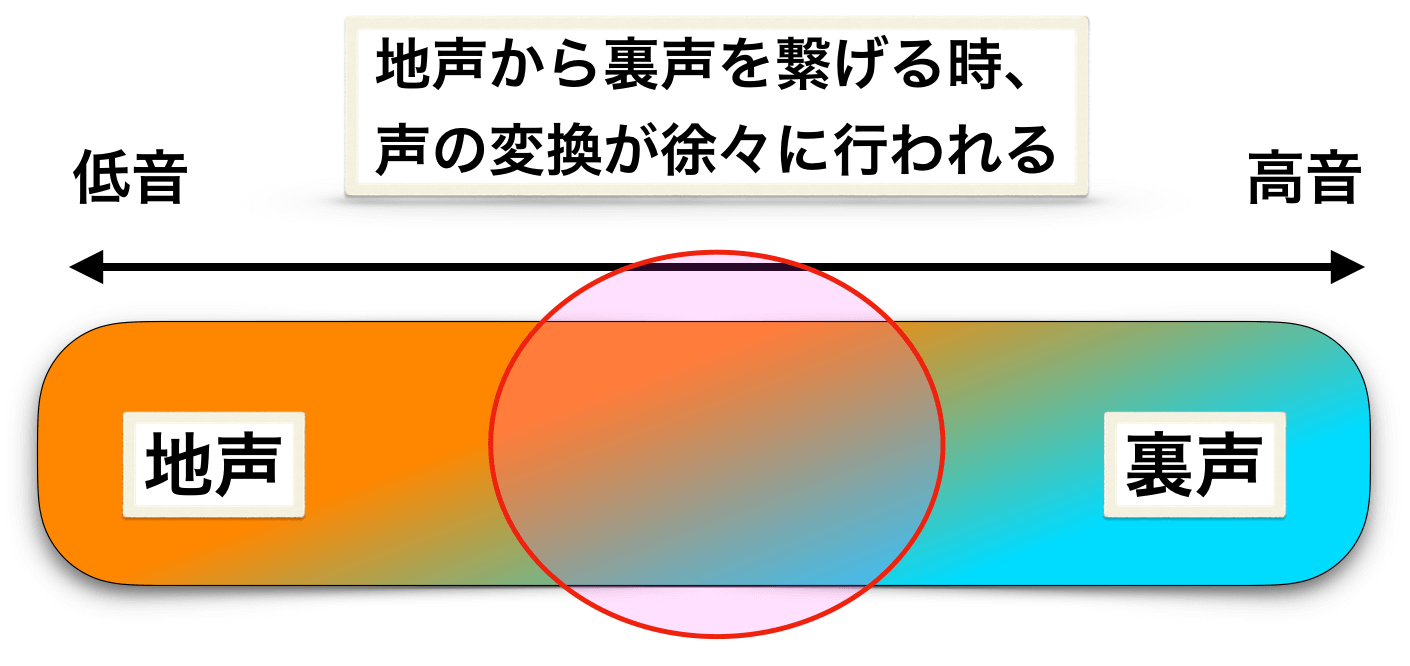
スムーズな力の調整(受け渡し)をするためには、地声と裏声を上手くコントロールする能力が必要になるということです。
なので、この自然な切り替えができる状態の能力になること、もしくはその技術を身につけることをミックスボイスと呼ぶ場合もあります。
表現においては、綺麗に繋ぐことが全てではない
一つ注意点なのですが、歌の中では、必ずしも地声と裏声を綺麗に繋がなければいけないというわけではありません。
地声と裏声の境目がはっきりしていたとしても、それはそれで良いということは多々あります。
ヨーデルなんかは、まさにそれを前面に出した歌唱方法ですよね↓
このように、地声と裏声を切り替える時の音が、音楽的な気持ち良さを生み出すこともあるので、「必ず地声と裏声を繋げなければいけない」というわけではありません。
繋げられる能力を持っているのは良いことですが、『綺麗に繋げるのか』『はっきりと分けて表現するのか』は表現次第ということです。
②地声と裏声を感覚的に混ぜる発声
状態は先ほどの声区融合とほぼ同じですが、今回は『発声』自体を指しています。
- 「地声」と「裏声」が感覚的に混ざっている発声
- 「地声」と「裏声」が重なり合っている付近の音域において、その二つの感覚的割合をある比率で分けたような発声
をミックスボイスとするということです。
例えば、先ほどのように、地声から裏声までを滑らかに繋げるように発声をします。
この時、その中間部分で、自分の感覚的には『地声とも裏声とも言えない感覚』もしくは、『地声と裏声をある比で配分したような感覚』になることがあります。
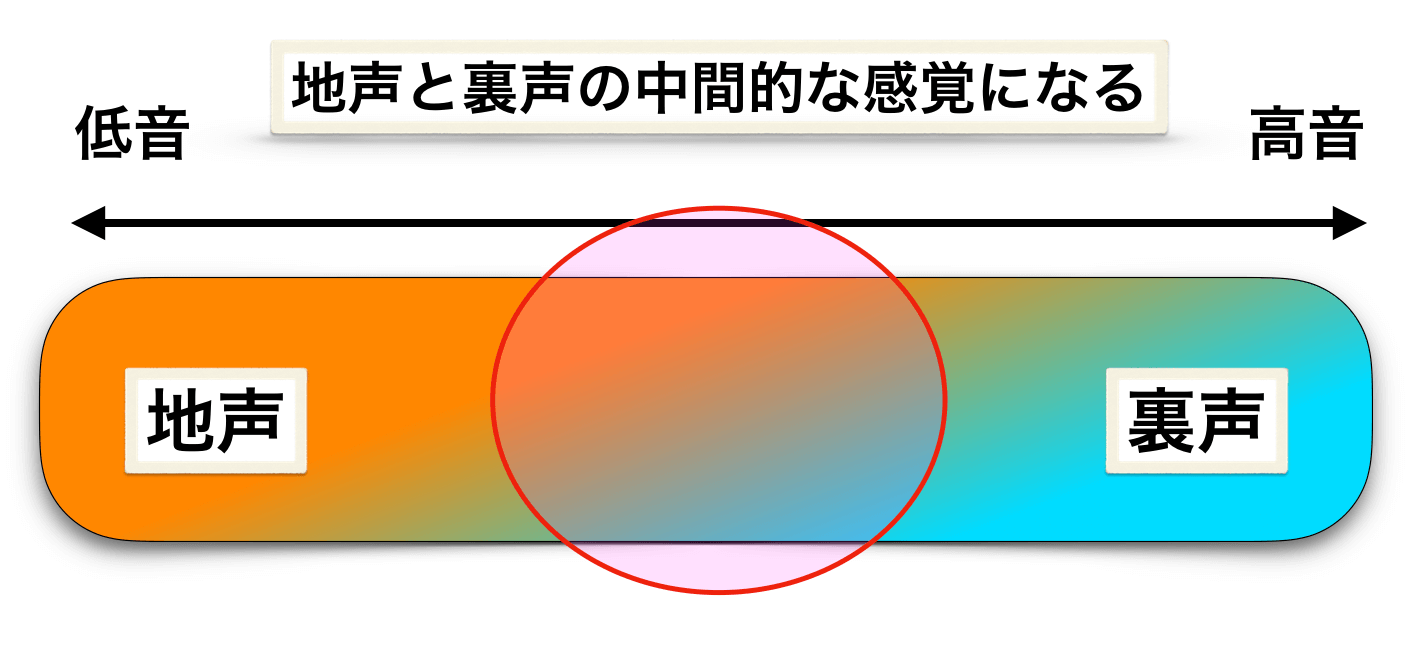
例えば、
- 地声:裏声=6:4
- 地声:裏声=5:5
- 地声:裏声=4:6
などのような感覚を持つということですね。
あくまでも、声帯の状態としては地声か裏声に区分されるのですが、自分の主観における『感覚的なミックス』をミックスボイスと呼んでいるということです。
確かに、感覚や意識の配分はある
人間の声帯は、基本的に『高音域になるほど伸びて薄くなり、自然と裏声になっていく』という仕組みになっています。
どんな人でも、必ず地声の音域の上に裏声が存在します(*「裏声が出ない」というのは別問題として)。
ということは、『高音に行けば行くほど、裏声に移行したくなる(裏返りたくなる)感覚になる』と言えます。

例えば、声が裏返るくらいの高音域帯において「地声のままにしようとする力(感覚)」を働かせると
- 地声のままにしようとする力(感覚)
- 裏声に行きたい力(感覚)
の二つが綱引き状態になります。
ある程度しっかりと力を入れれば地声のままでいられるし、完全に力を抜けば裏声になるという感じです。
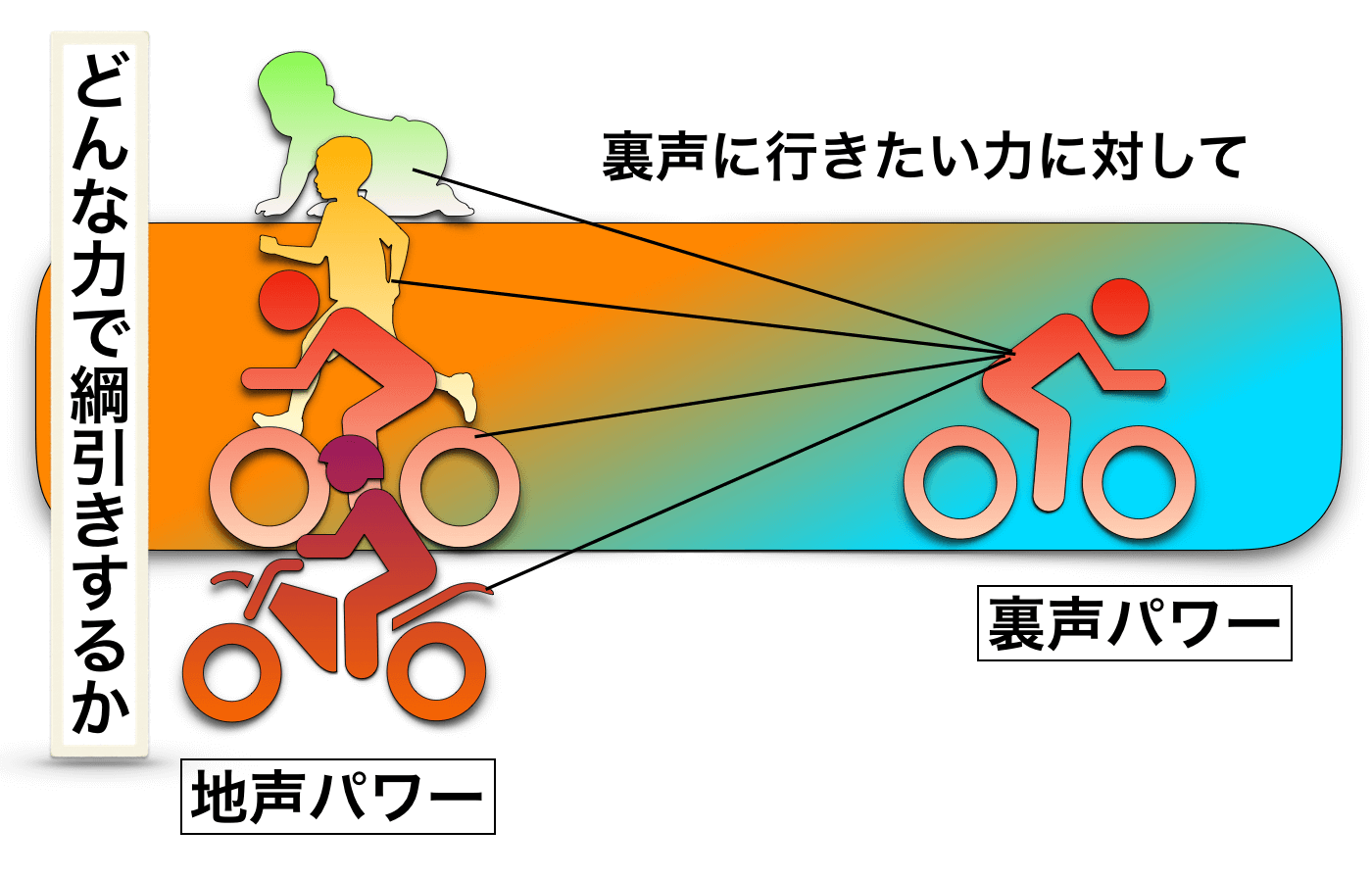
ここで、地声から裏声までを綺麗に繋ごうとすると、この綱引きのバランスを徐々に変換させていかなければいけません。
この変換が行われている時、「地声」と「裏声」をある割合で分けたり、混ぜたりするような感覚を持つことはあります。
感覚的に考えること自体は何も問題ないですし、多くの人は意識すれば多かれ少なかれこのような感覚を理解できるでしょう。
しかし、発声を指す言葉としては曖昧すぎる
このような「地声と裏声の感覚が混ざった発声」のことをミックスボイスと呼ぶ場合の問題点は、
- 『どの割合までがミックスボイスなのか』をはっきり定義できないこと
- 発声している本人以外には感覚が判断できないこと
です。
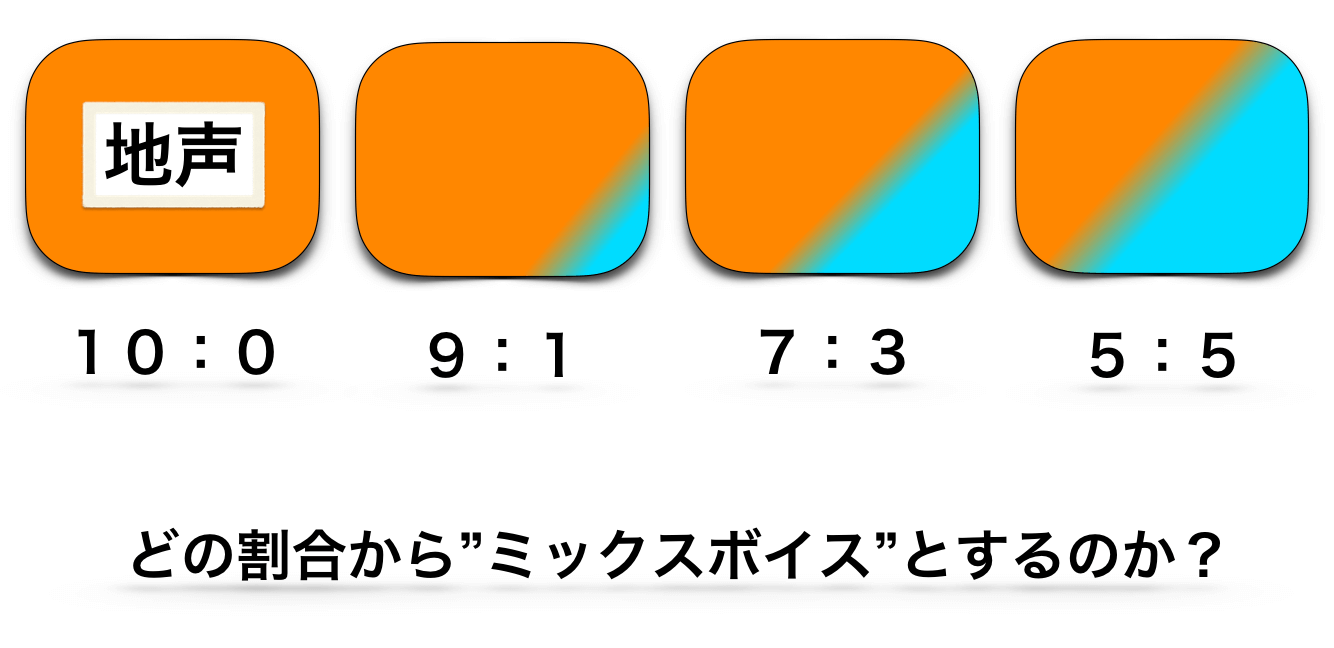
例えば、【地声:裏声=9:1の発声】。
- これは「地声」なのか「ミックスボイス」なのか。
- そもそも純度100%の「地声」「裏声」の定義とは?
などの問題が生まれます。
極端な話、感覚を混ぜていれば【9.99:0.01】でもミックスという考え方もできるわけです。
「そこまで細かいことは気にせず、【7:3】【6:4】【5:5】あたりをミックスボイスと呼べばいいんだよ。」と思うかもしれませんが、そうなるとミックスボイスは結局『個人個人の感覚次第で決まるもの』ということになってしまいます。
つまり、
- 自己申告でしか成立しないもの
- 他人には判断できないもの
です。
これを発声名としてしまうと、非常に扱いにくいですし、個人差が大きすぎて、様々な誤解や混乱を招いてしまいます(*すでにそうなっていますが)。
中間的な感覚を持つこと自体は問題ではないのですが、発声自体を指してしまうと上手く定義できず、曖昧な言葉になってしまうということです。
③地声の高音発声
これは、
- 地声の高音発声
- 裏声ではない高音発声
のことを指します。
例えば、こんなイメージ(*再生位置、0:50〜)↓
高音発声ですが、明らかに裏声には聞こえませんし、地声のように聞こえるはずです。
こういう高音発声のことを「ミックスボイス」と言うのであれば、そう呼ぶこと自体は特に問題ではありません。
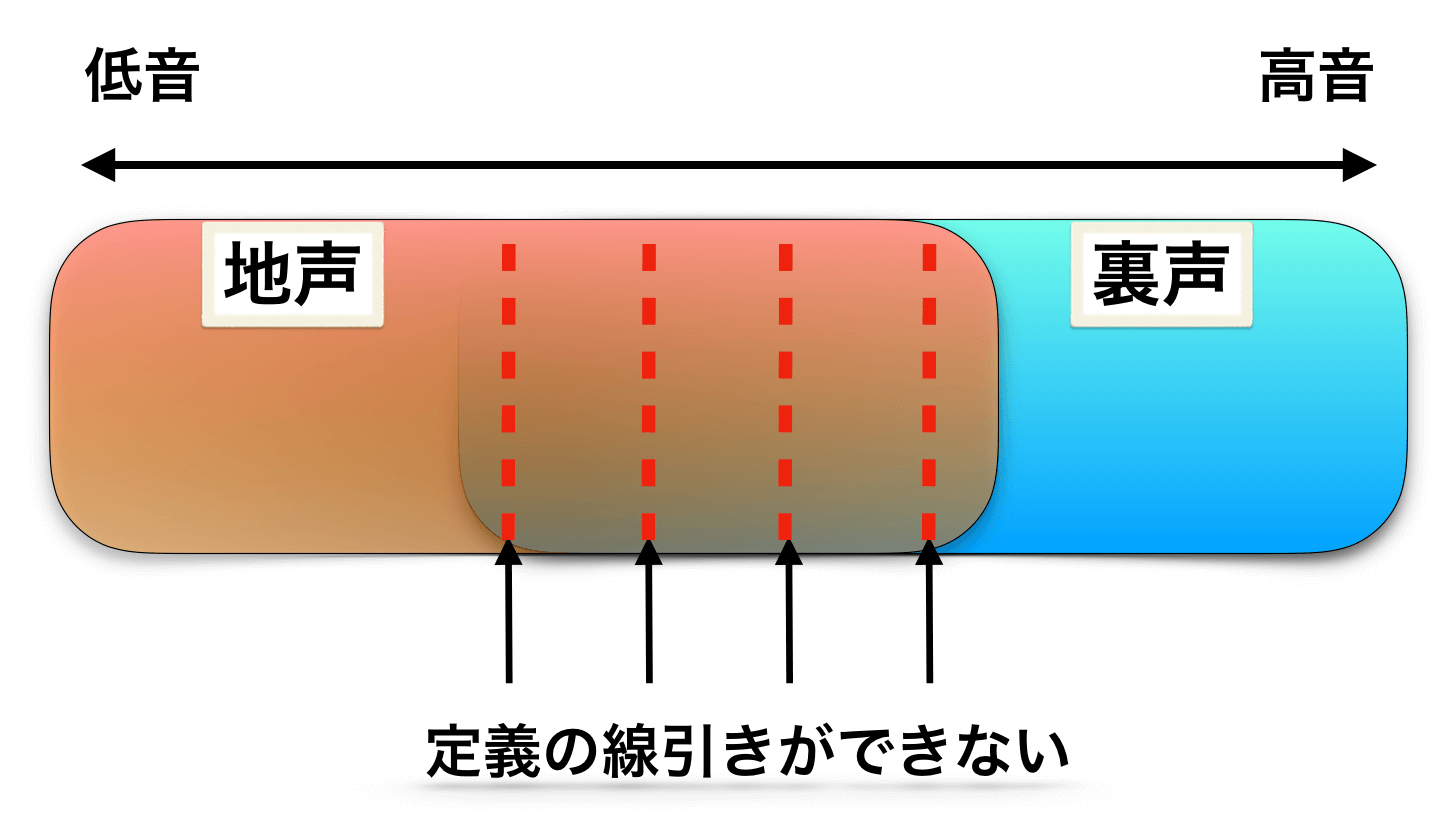
ただし、この場合の問題点は
- 『地声(低音域)との差』をはっきりと定義できないこと
です。
どこまでが地声で、どこからがミックスボイスなのか、をはっきりと示すのが難しい。
先ほどの動画でも再生位置で『Mixed/Belted』『ミックス/ベルト』という風に複合的に表現していますね。ベルトは『ベルティング』のことで、主に地声の高音(地声の声を張った発声)を指す言葉です。
低音域も高音域も地声は地声であって、そこに何かわかりやすい線引きを探すのは難しいです(*再生位置9:13〜)↓
明確な区切りをつけられない以上、それは『地声の高音』となんら変わりなく、「地声の高音じゃん。何が違うの?」と言われれば、答えに困るでしょう。
つまり、これもはっきりと定義できないのが問題ということです。
「個々の声帯の特性」を考えない場合、地声だとは信じられない?
思うに『個々の声帯・喉の個性を意識するかどうか』が、このようなミックスボイスの考え方に影響しやすいだろうと思います。
以下に二つの正反対の考え方がありますが、皆さんはどちらの考え方でしょうか?
- 人はそれぞれ持っている体(声帯や喉)が違うので、声の特性・個性にも違いがある。なので、それぞれ得意な音域・得意な声質にも違いがあり、魅力的に歌える音域や声質には人それぞれ鍛えられる限界がある。
- 人は持っている体(声帯や喉)に関係なく、鍛えればどんな音域でもどんな声質でも魅力的に出せるようになる。どれだけ自分の声の個性とかけ離れた目標でも、トレーニングさえすれば、目標の歌声になることができる。
①の考え方が強い人は「ミックスボイス」という概念を持ちにくく、②の考え方が強い人は「ミックスボイス」という概念を持ちやすくなるのかもしれません。
例えば、高い歌声の男性ボーカルは”ミックスボイス”と言われやすいです(*「話し声」と「歌声」に着目してみてください)↓
しかし、こういう高い音域の歌声は、
- 「高い声帯のタイプ」「もともと高い声」という個性を持っている人の”地声”なのか
- それとも、トレーニングして作り上げられた”ミックスボイス”なのか
どちらで考えるべきでしょう。
例えば、バイオリン・チェロ・ビオラ・コントラバスなど楽器の形や特徴が違うのと同じように、人の声帯も形や大きさ、その音色の特徴はバラバラです。
男女の違いはもちろん、同性であっても「声がすごく低い人」から「声がすごく高い人」まで様々な人がいます。
そう考えると、
やはり『”人それぞれの声帯の個性”を均一化して考える』のは無理があると言えるでしょう。
確かに、すごく声が低い人であれば「あんな高音を地声で出すなんてありえない。これは特殊な技法で出しているミックスボイスという発声だ」と考えてしまう気持ちはわかります。
同じ性別でも声が低い人と声が高い人を比べれば、ものすごく落差がありますから(*世界一声が低い男性)↓
しかし、「地声であんな高音はありえない」という考え方は『持っている楽器(声帯)は人それぞれに違う』という視点が抜けてしまっていると言えます。
例えば、もともと高い声が出せる人のことを『天然ミックスボイス』と呼んだりしますが、これも個々の声帯の違いをあまり考えない結果として生まれたのでしょう。個々の声帯の違いを考慮に入れれば、単に『元々高い声帯を持つ人』と言えるはずです。
このように『声帯の個性』を考慮に入れるかどうかが、ミックスボイスの考え方に関わってくると考えられます。
④裏声の低音発声
これは先ほどの裏声バージョンで、
- 裏声の低音発声
- 地声ではない低音発声
のことをミックスボイスと呼んでいるパターンです。
「ミックスボイスは裏声を地声っぽく聴かせているもので、元々は裏声だ」という考え方の場合は、これに当てはまることが多いかもしれません。
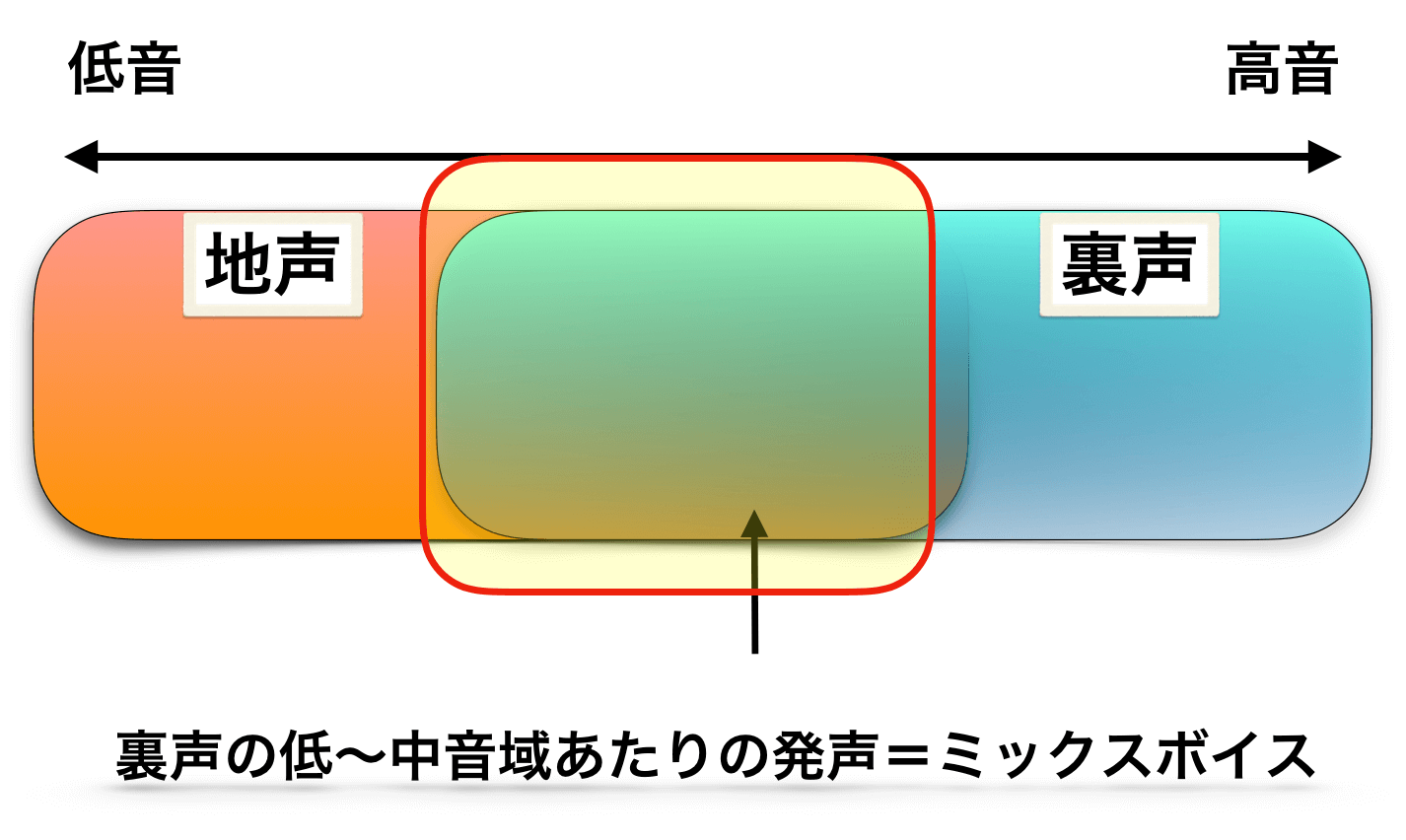
こちらも先ほど同様に、そう呼ぶこと自体は何も問題ありません。
ただし、同じように定義の線引きができないのでその点が問題です。
低音域だろうが、高音域だろうが、裏声は裏声だと言えるはずです。
⑤地声と裏声の中間的な声質の発声
これは、地声と裏声の中間的な声質の発声をミックスボイスとするということです。
音程は関係なく、声質の印象が地声と裏声の中間であるという考え方です。
この考え方では主に、
- 柔らかい音色の発声
- 透明感のある音色の発声
の二つをミックスボイスとすることが多いです。
柔らかい音色
例えば、こういう歌声↓
このような少しマイルドな柔らかさを持った発声は、「地声らしさ」と「裏声らしさ」が混じっているような音色なので「ミックスボイス」とするという感じでしょう。
透明感のある音色
例えば、こういう歌声↓
話し声と音色の落差が大きく、すごく透明感のある音色の発声です。これも、先ほど同様「地声らしさ」と「裏声らしさ」のある音色に感じるのでミックスボイスとする、という感じでしょう。
こういう発声は、話し声と歌声の落差が大きいので、何か特殊な発声方法で発声している(=ミックスボイス)と考えやすいですが、そういうわけではありません。
これは、電話に出るときの声の変化の上位互換だと考えるといいでしょう。
例えば多くの人は、知り合いではない人の電話に出るときなど普段の話し声から変化しますよね。
他人との電話の声というのは、普段よりハキハキしたり、やや音程を上げたりして「自分のいい声」を作っているでしょう。そして、このときの声は『地声』のはずです。
この「普段の声」を「電話用の声」に変化させるようなものを、さらにグレードアップしたものが「歌声用の声」です。
特に、プロのシンガーの歌声は電話用の声とは比べ物にならない良い声を作り上げるので、声が変わったと感じることも多いですが、裏声でなければそれは「磨き上げられた地声」だと言えます。
「柔らかい声質」も「透明感のある声質」も”ミックスボイス”と呼ぶこと自体は問題ないのですが、そう呼ぶ必要性はあまり感じられません。
⑥共鳴位置が中間にある「地声」のこと
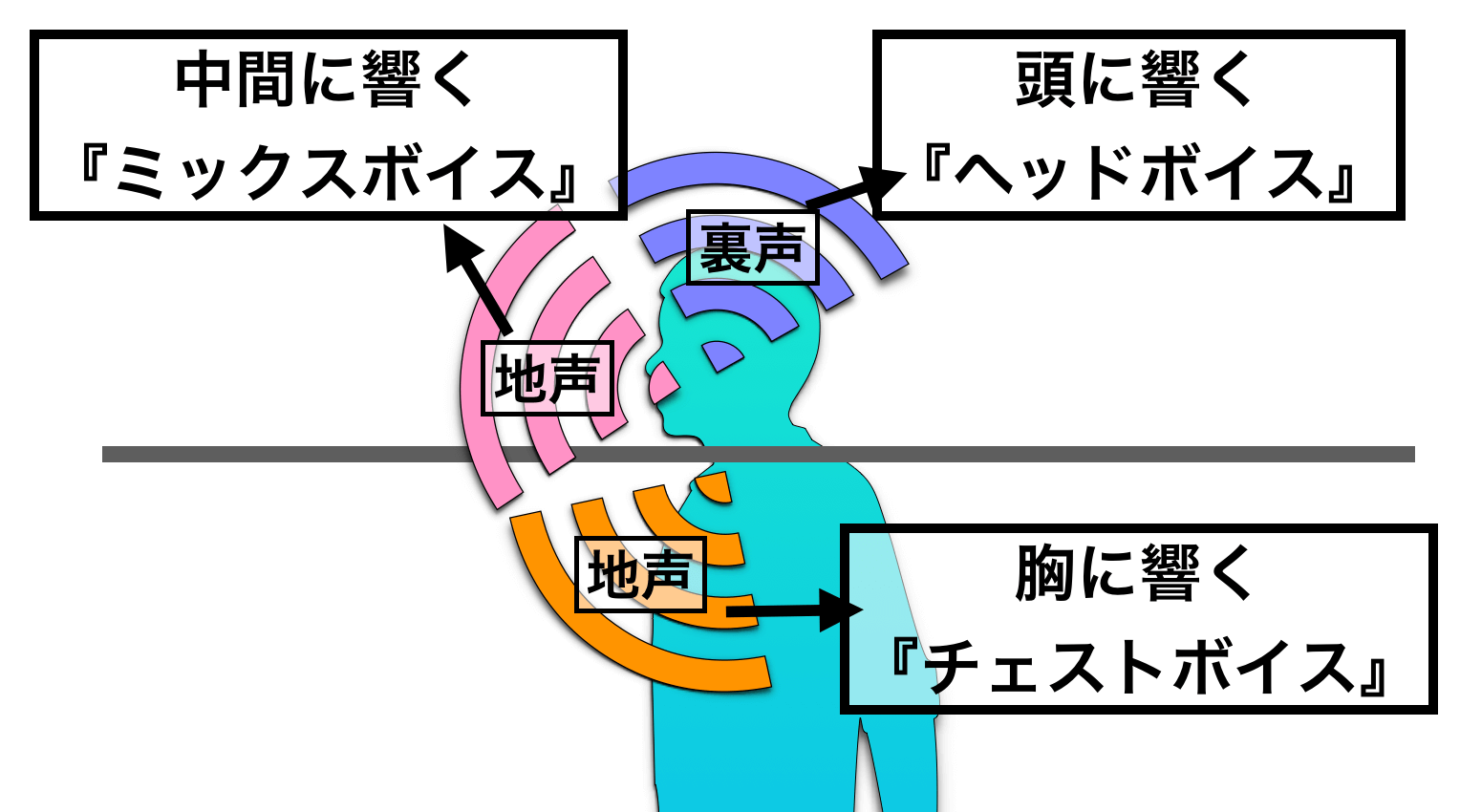
これは、「地声」における響きの位置が中間に響く発声をミックスボイスとするということです。
つまり、『共鳴感覚が中間地点にある発声』ということです。
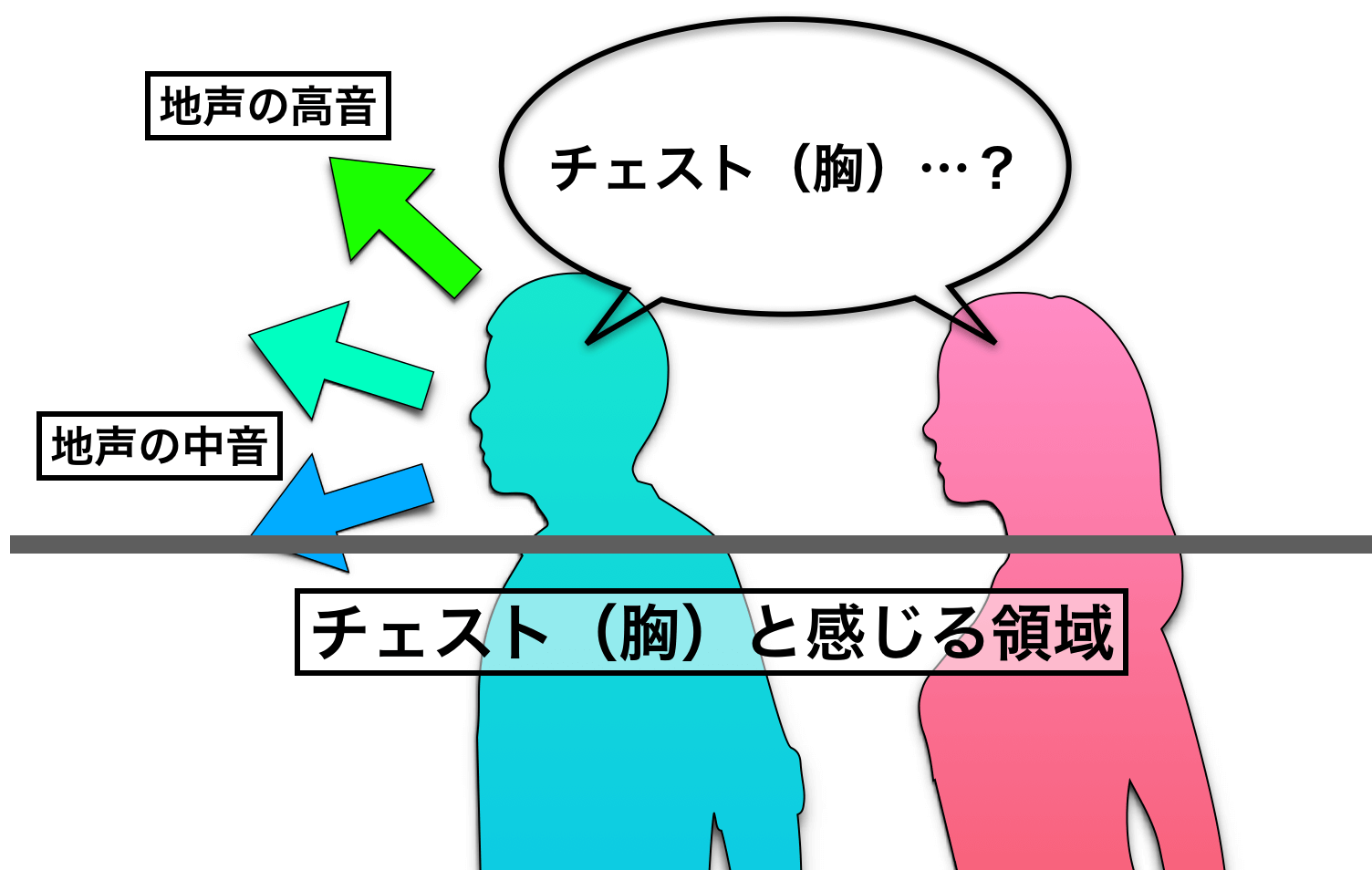
まず、地声は『チェスト(胸)に響く声』なので、チェストボイスと呼ばれます。同じように、裏声も『ヘッド(頭)に響く声』なので、ヘッドボイスです。
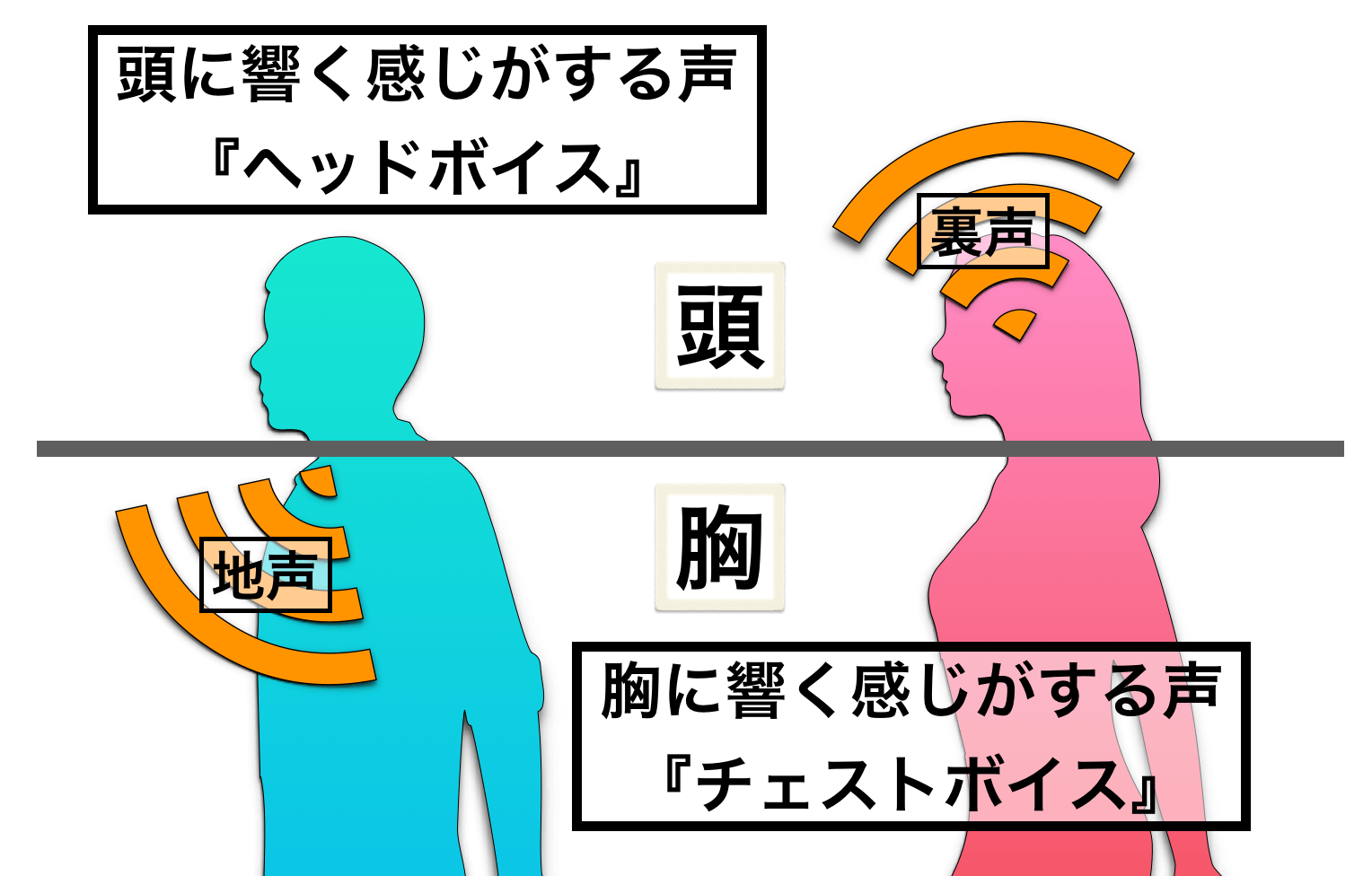
これは端的に言葉の特徴を表している言葉ですし、そういう概念の言葉でもあるので特に深く考える必要はありません(*ヘッドボイスは、異なる考え方もあります。詳細は『ファルセットとヘッドボイスの違いについて』)。
ところが、特に歌の指導や練習などにおいて、その言葉と深く向き合えば向き合うほどに言葉の意味がしっくりこなくなることがあります。
例えば、地声で最低音から最高音まで発声すると、声が響く位置(声の方向性)が感覚的に真下からだんだんと上に上がってくるのがわかるはずです。
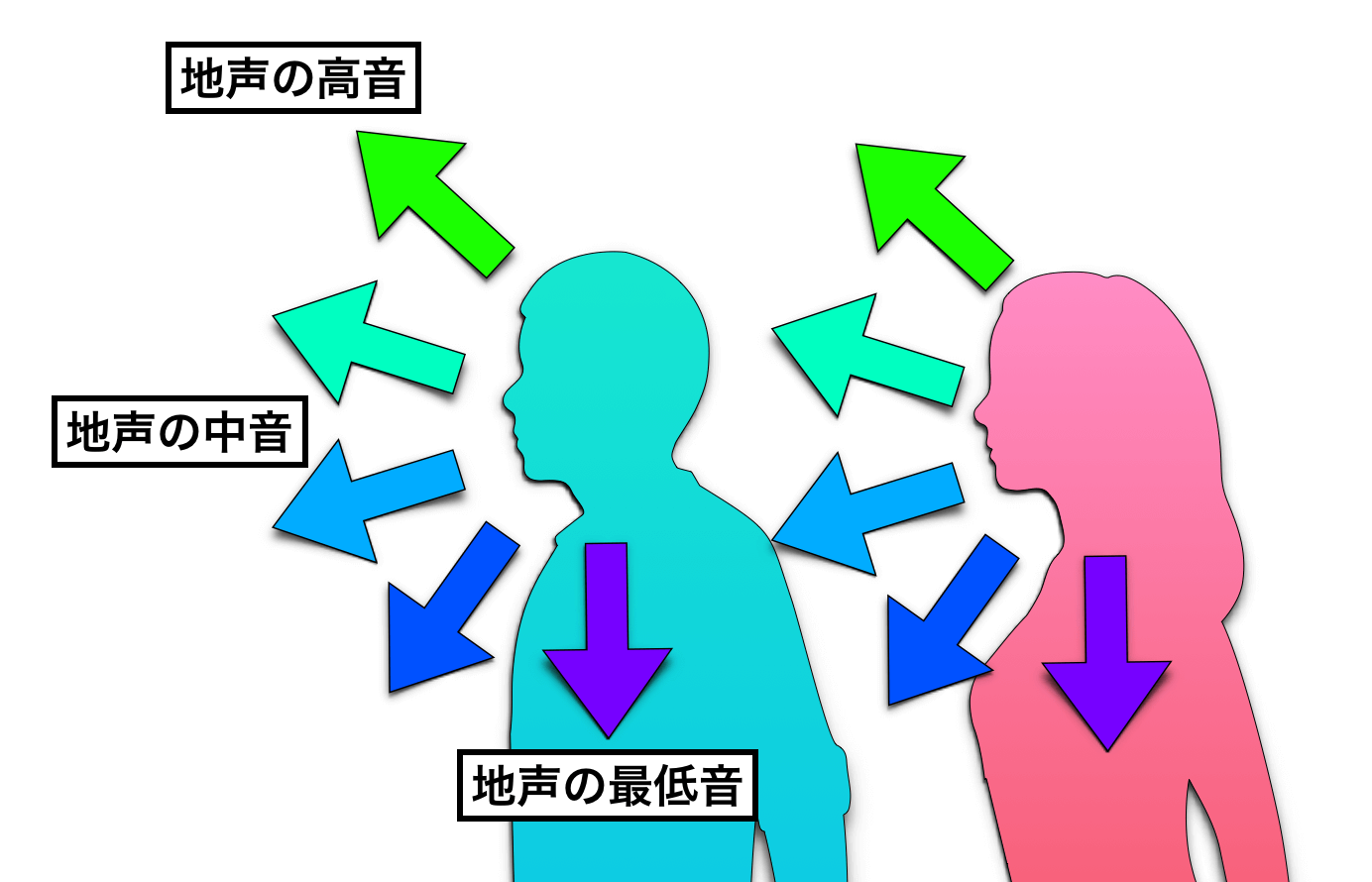
この時、「低中音域は胸に響く感じがするが、中高音域あたりはほとんど胸の響きを感じず、顔の前部分、もしくはおでこ方向に響きを感じる」という状態になります。
こうなると、『チェスト・胸』という言葉自体がどうもしっくりこなくなるのですね。
真剣にそれと向き合い深く考えることで、言葉の意味がおかしく感じるのです。
日本語で言えば、「地声…地声…”地”って何?」という状態です。
なので、歌の指導などにおいて、地声における中間の響きを表す言葉として『ミドルボイス・ミックスボイス』という言葉が使われるようになったと考えられます。

おそらくは「ミドルボイス」が先にきて、「ミックスボイス」と都合よく結びついたのでしょう。
この中間的な共鳴位置を「ミックスボイス」と呼ぶこと自体は問題ないのですが、ややこしいので「ミックスレゾナンス」「ミドルレゾナンス」と呼んだ方がわかりやすくて良いのではないかと思います。
⑦共鳴位置が中間にある「裏声」のこと
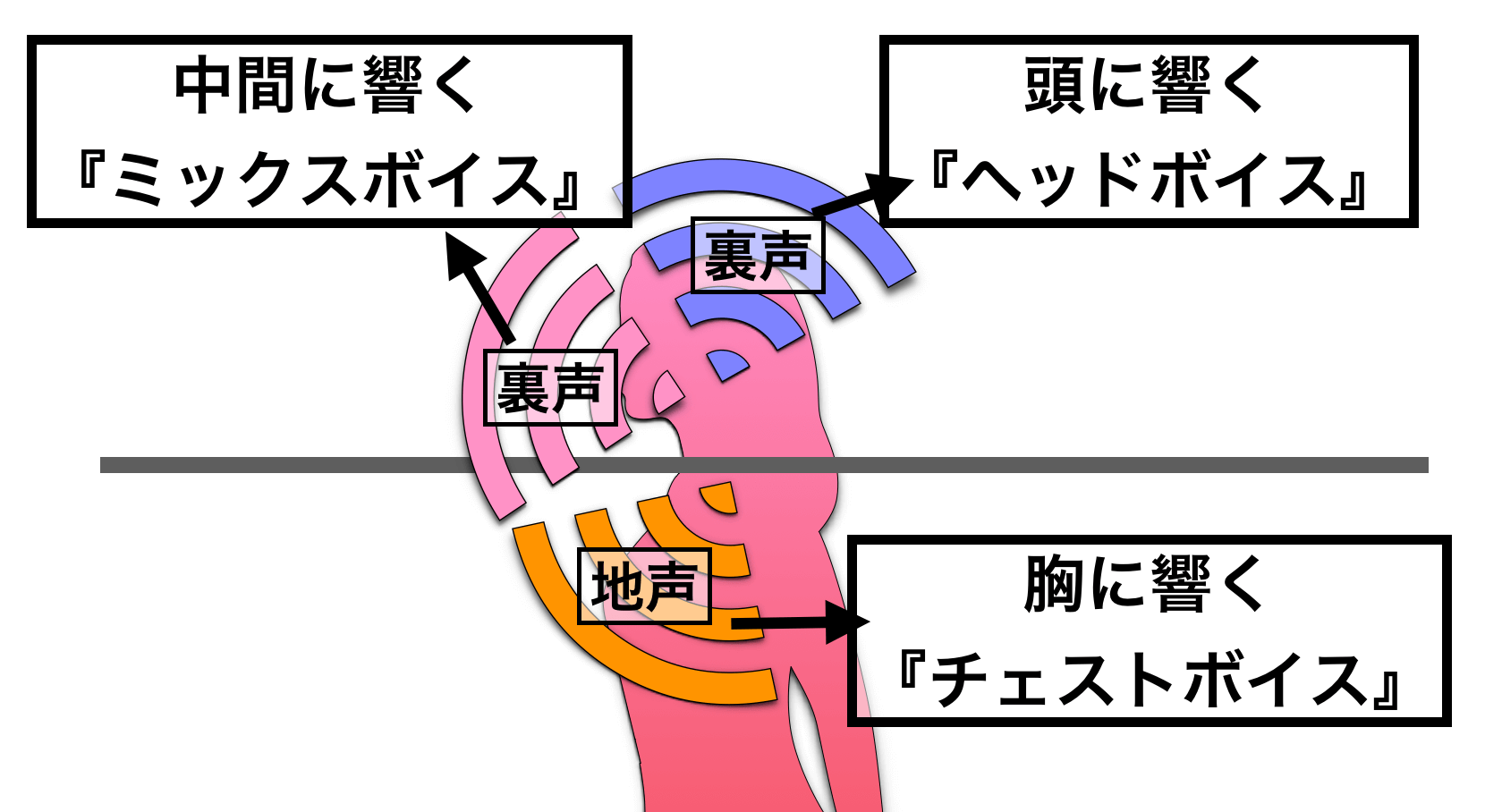
これは、先ほどの「裏声」バージョンということです。
裏声も地声と同様にそれが低中音域になったときに、『ヘッド』と呼ぶにはふさわしくない位置に響きます。
これによって、先ほどの地声と同様の理屈で「中間位置に響く裏声」という意味でのミックスボイス・ミドルボイスになるということです。
こちらもそう呼ぶ分には問題ないのですが、ややこしいですね。
⑧地声と裏声の間を埋める発声(=間にある『声区』)
これは「地声と裏声に間が空いている」「地声と裏声が飛んでしまう」という状態において『その間を埋めるものがミックスボイスである』という考え方です。
地声と裏声の境目に着目して↓
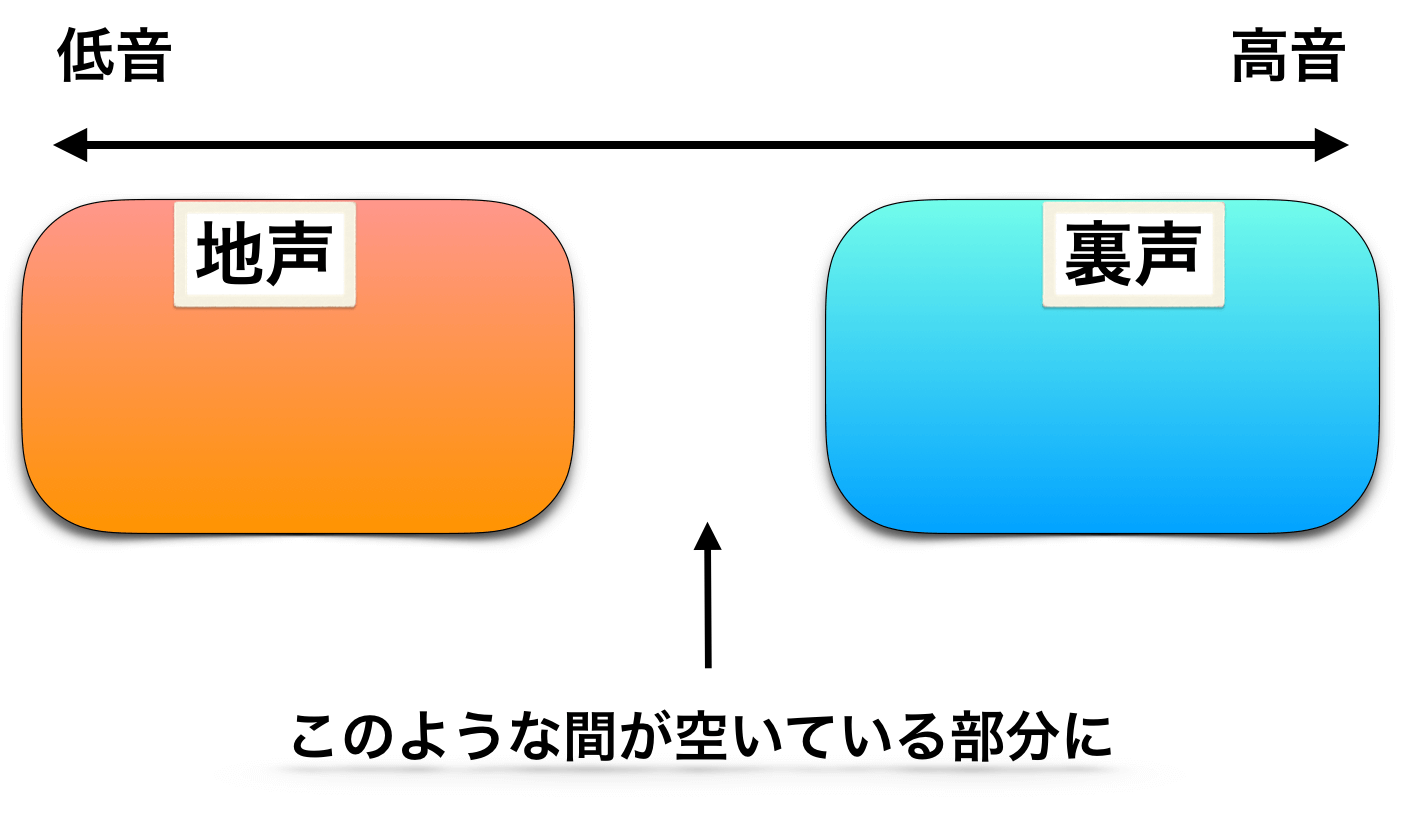
ミックスボイスというものが入り込んで、間をつなぐ役割をするという考え方↓
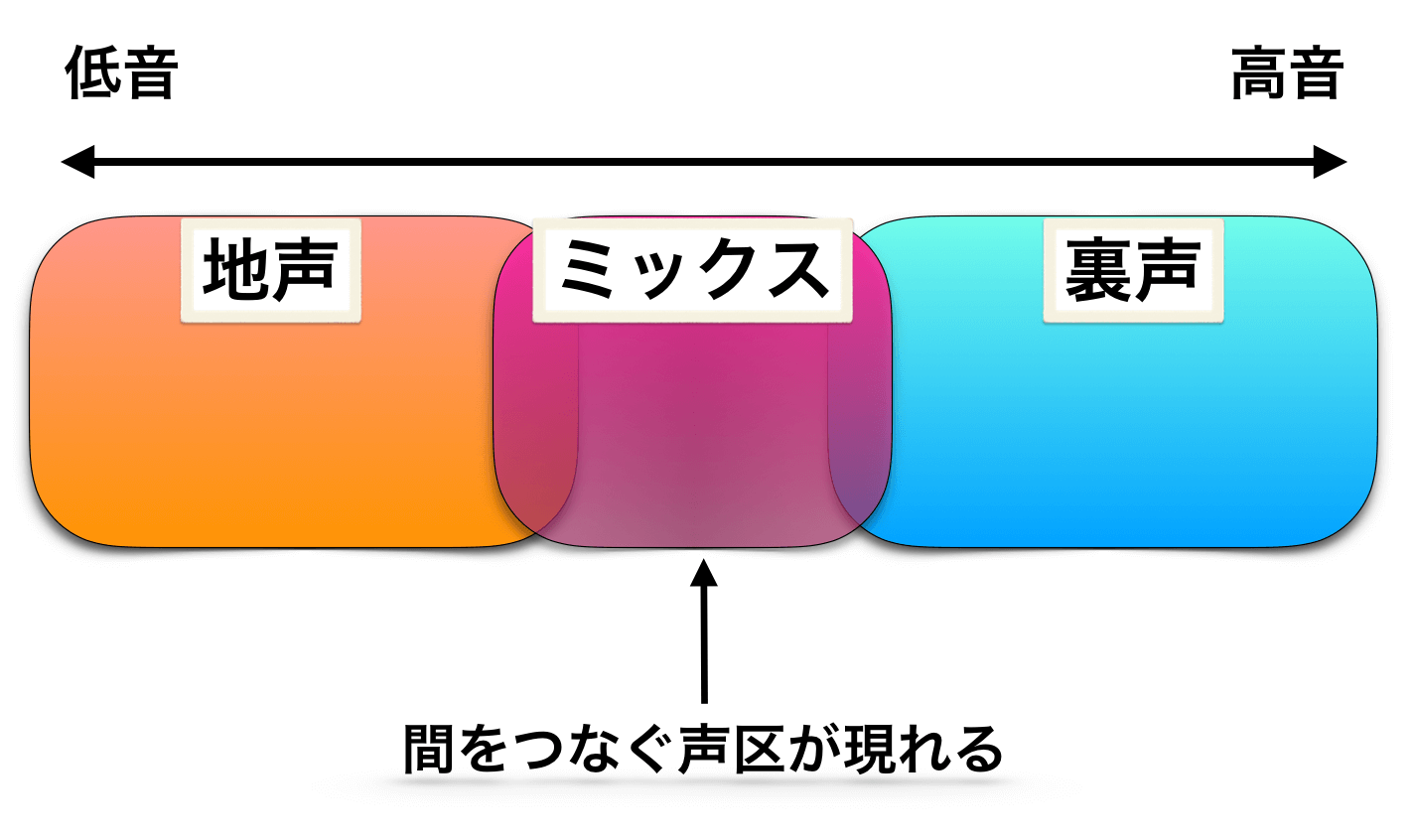
しかし、このような間を埋めるために必要な『声区』として考えるのは無理があるし、歌の成長にとってあまり良くないだろうと思われます。
その理由は、
- 地声と裏声の間に声区はないから
- 鍛えれば地声と裏声の音域は重なるから
です。
一つ目は、冒頭で説明した通り『現在の定説では、声区ではない』ということ。
そして、二つ目の『鍛えれば地声と裏声の音域が重なる』という点からも、その間に声区が必要とは言えないのですね。

現状、地声と裏声の間が大きく空いてしまっている人は「そんなバカな」「無理無理」と思うかもしれませんが、鍛えれば地声と裏声の音域はしっかりと重なります。
なんなら、歌に全く興味がない人や、声のトレーニングを全くしたことがない人にも地声と裏声が重なっている人は普通にいます。
おそらく、探せば家族や周りの友人の中にも見つかると思いますので、そうレアな現象ではありません。
当然ながら、同じ音階で「地声」と「裏声」を出すことも普通に可能です(*再生位置4:56〜)↓
ジェシー・Jさんが声区の説明をしていますが、「ヘッドボイス(裏声)」と「チェストボイス(地声)」で同じ音階を出していますね。
つまり、地声と裏声の音域が重なる時点で、「その間を埋めるためにミックスボイスを身につけなければいけない」という考え方には問題があるのですね。
しかし、
『地声と裏声の間に声区をはっきりと認識できる』『明らかに地声とも違う、裏声とも違う、その間にある発声を出せる』という人もいると思います。
この「なぜ地声と裏声の間に声区があると感じる人がいるのか?」という点を掘り下げておきます。
地声と裏声の間に声区があると感じる理由
100%とは言えませんが、地声と裏声の間に声区を感じる主な理由は、
『不完全な地声』をミックスボイスだと感じているから
だと考えられます。
そして、「不完全な地声」を身につけやすい人は、
- 声帯の柔軟性(声帯の能力)が低い場合
- 自分の声帯の音域を無視している場合(特に声が低い人)
という二つのパターンです。
つまり、「声帯の柔軟性が低い人」と「自分の声帯に逆らっている人」がミックスボイスを認識しやすいということになります。
それぞれ掘り下げます。
①声帯の柔軟性が低い場合
まず、ここでの声帯の柔軟性とは、主に『声帯を伸ばす能力』のことを指します。
声帯は伸びると高音になり、縮むと低音になるので、声帯を伸ばす能力は音程調節の主役になります。

例えば、ある人が現状では声帯の柔軟性が低いとします。当然、声帯を伸ばす能力が低いので、早い段階で声が裏返ることになります↓
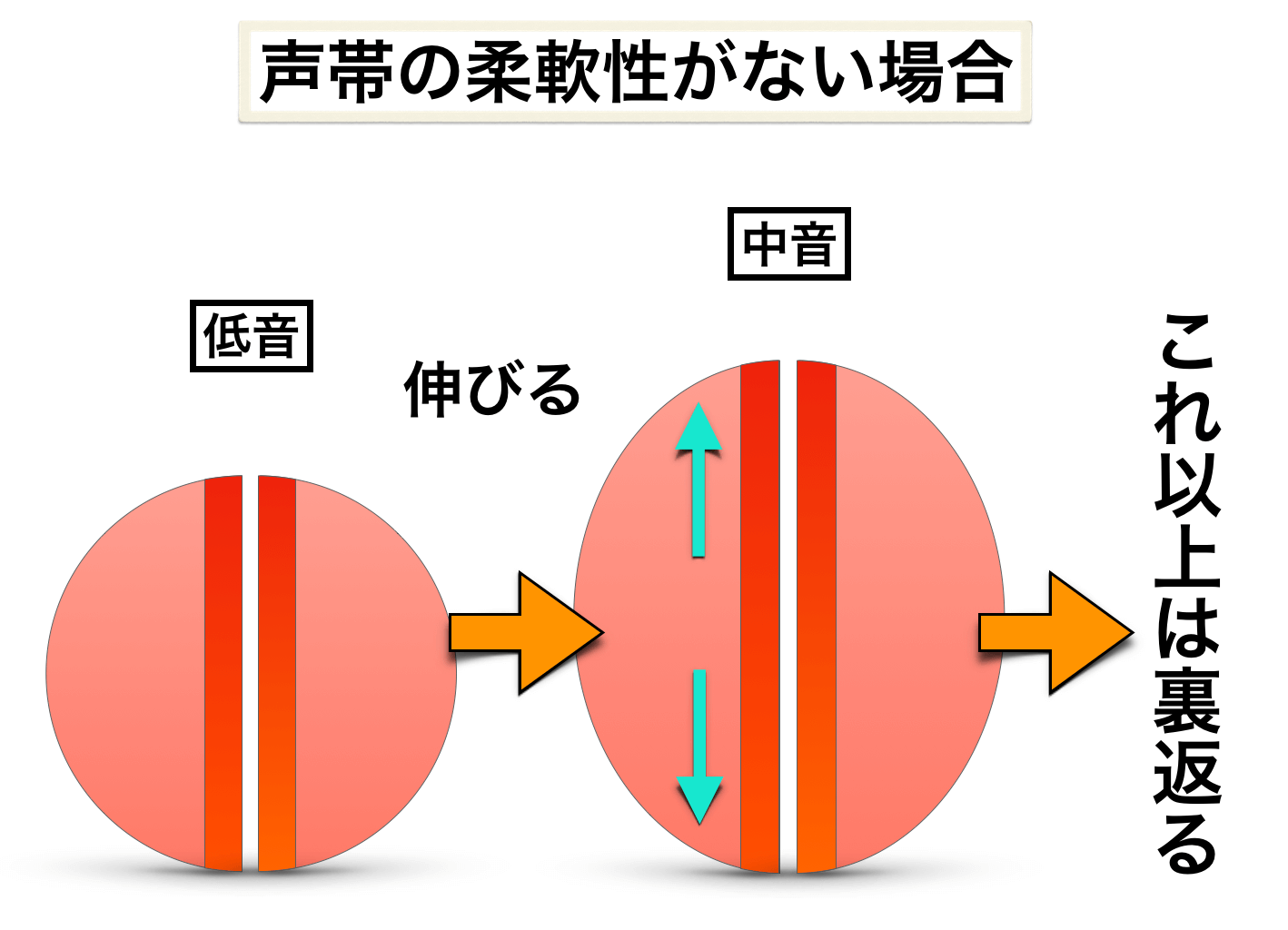
つまり、地声の音域が狭いのですね。
しかし、この人がしっかりとトレーニングを積めば、声帯の柔軟性が高まり、裏返るまでの音域に余裕ができます↓
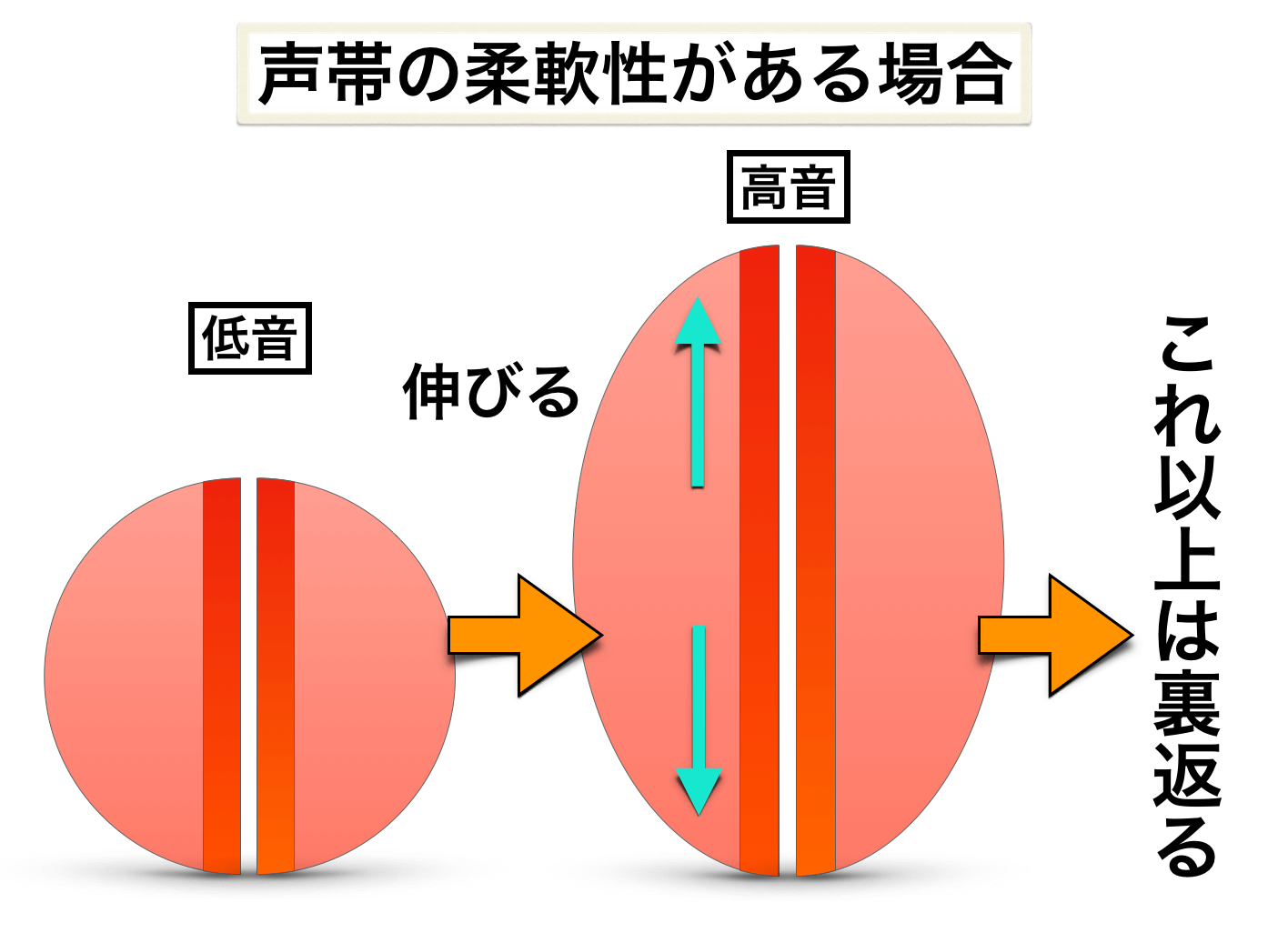
つまり、地声の音域が広がる。
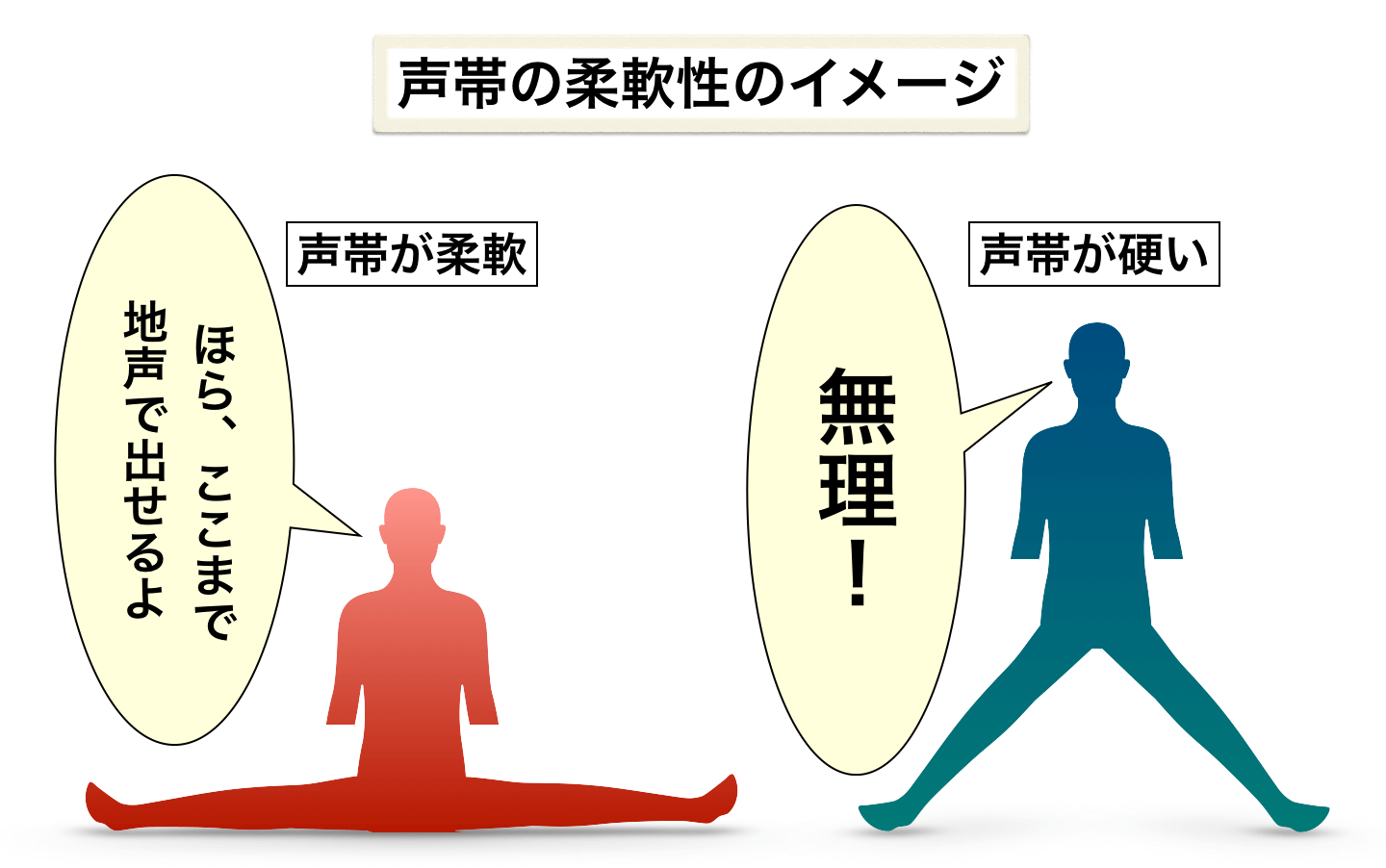
このように声帯の柔軟性は、その人の『地声における声帯をスムーズに伸ばせる範囲』に差をつけます。
これは、体が柔らかい状態と硬い状態の違いのようなイメージをするとわかりやすいかと。
注意点
声帯の柔軟性は「hiCまで出せるから柔軟性が高い」「mid2Eまでしか出せないから柔軟性が低い」などのように音階によって決まるわけではありません。
柔軟であればあるほど、音域が広いのは間違いないのですが、最高音が高いとは限りません。音域の位置は人それぞれ違います。詳しくは『音域はどこまで鍛えられるのか』の記事にて。
話を戻します。
先ほどの声帯の柔軟性が低い人が、今の能力のままで裏返らずに高音を出すにはどうすればいいか?
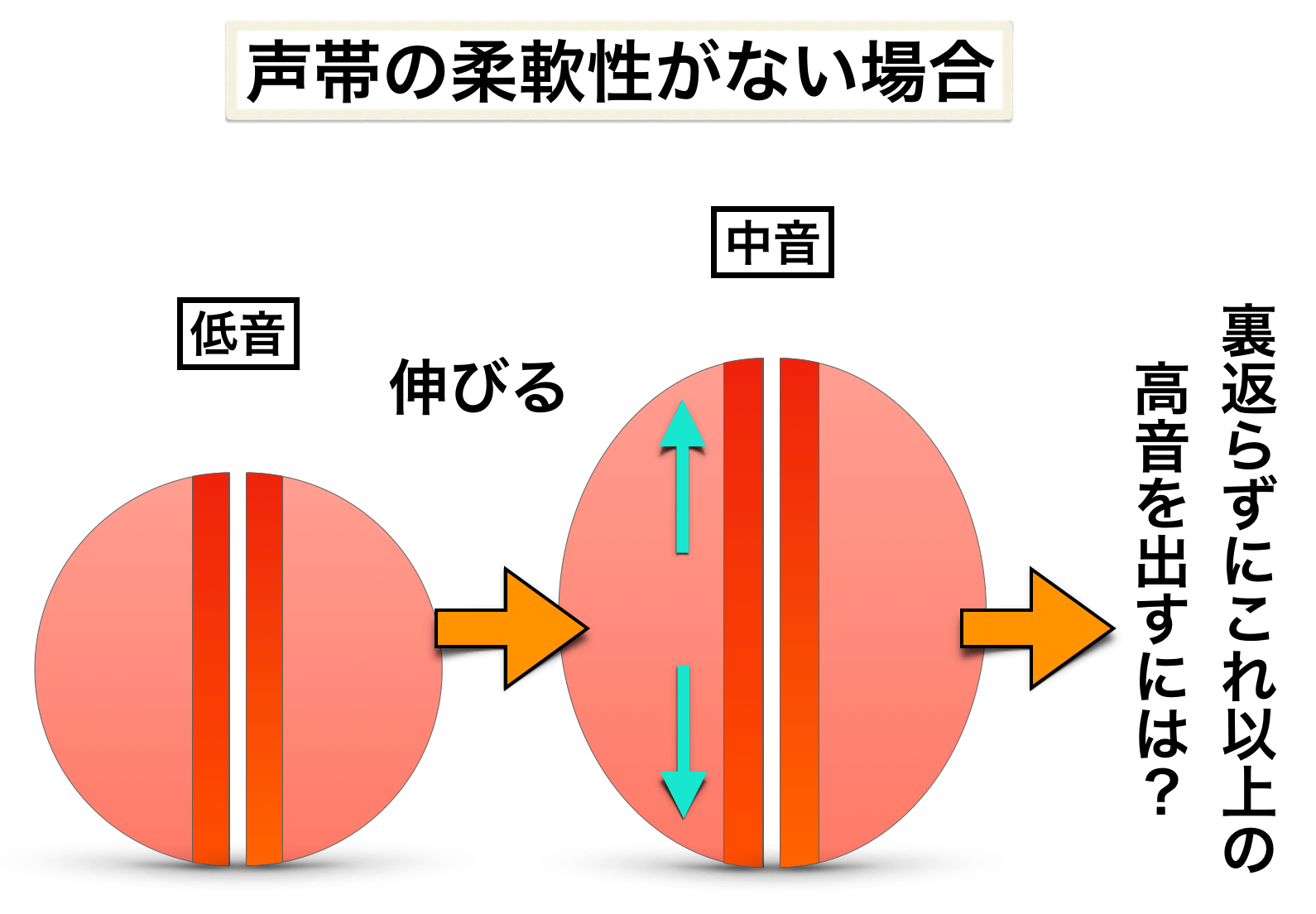
これ以上伸ばすと裏返るのなら、選択肢は『喉を締めて声帯を硬くする・緊張させる』しかありません。
つまり、伸ばせないなら『締める・固める』ということです(*高い声で喉が締まる原理)↓
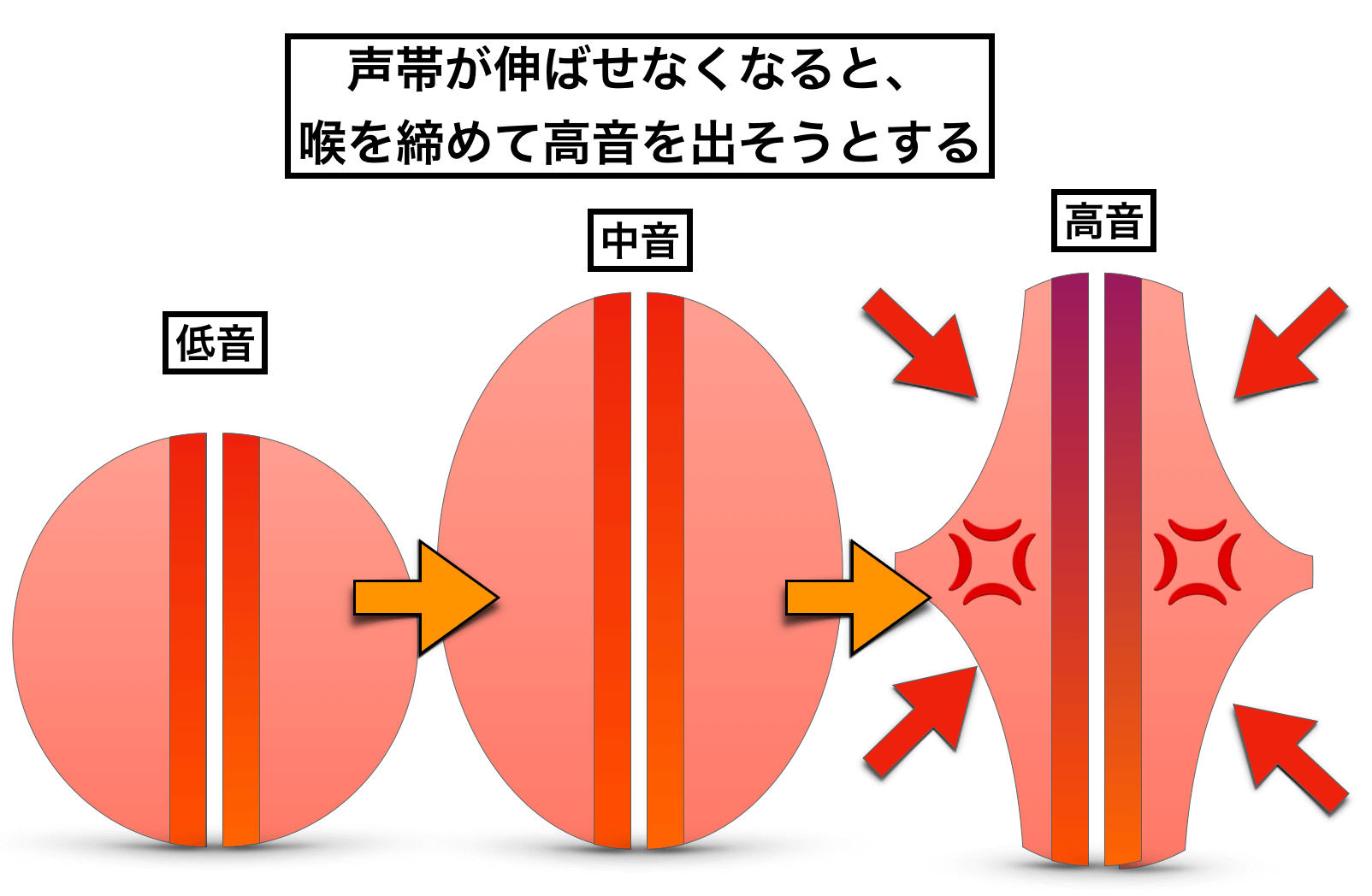
とにかくこれで、裏返らずに高音を発することはできます。
*なぜ締めると高い音になるのか?というのは、声帯硬く緊張させることで声帯の振動領域が狭くなり、振動数が上がるからです。針金などを指で弾くと「キン」という高い音がするように、硬い物体が振動する方が音が高くなります。
しかし、この発声状態はいわゆる「喉締め発声」であり、聴き心地が良くないので歌には使えません。
喉が締まらない地声域を上手く広げれば問題ないのですが、この時、トレーニングによって外側の締まりだけを上手く取り除いたような発声を生み出してしまう人が一定数います。
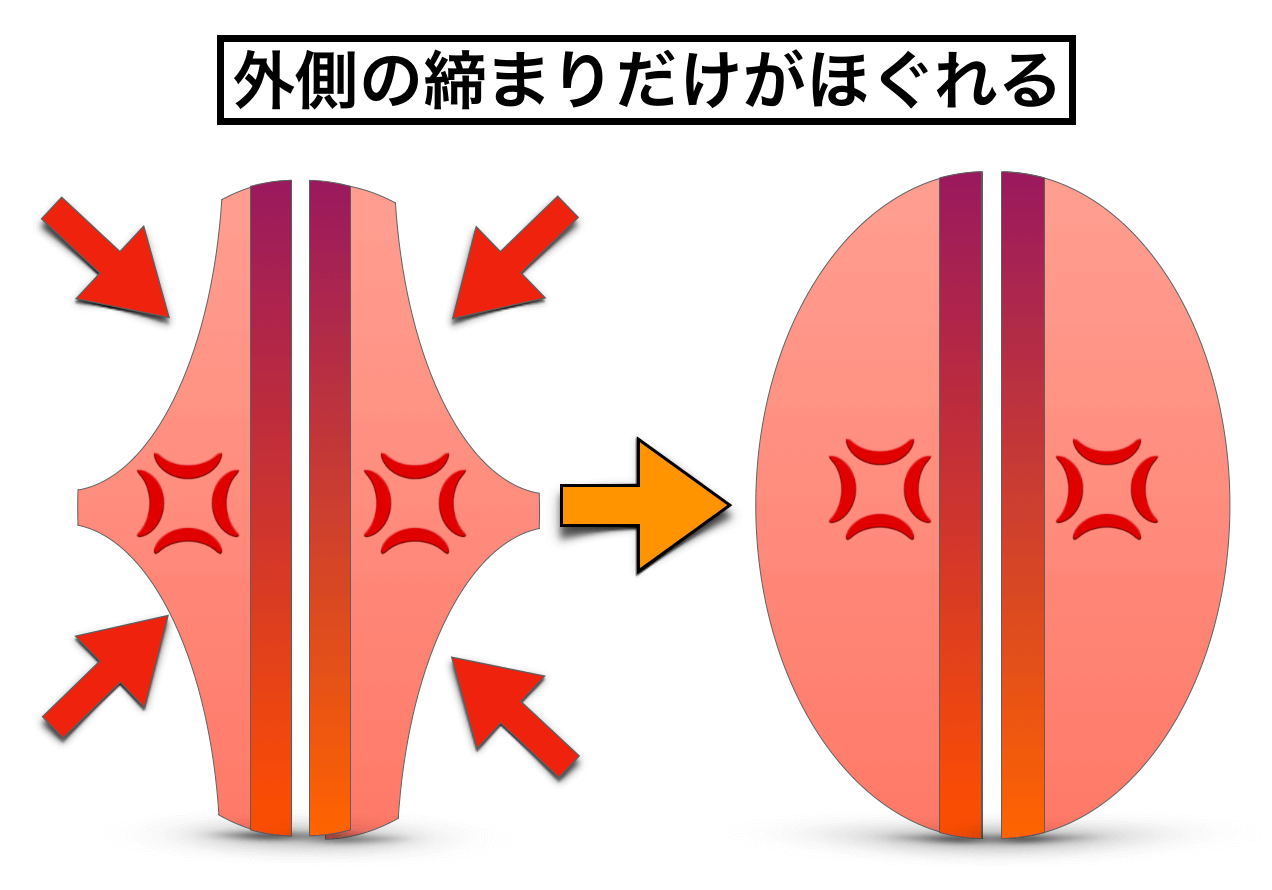
特に、「喉が締まらない範囲の発声まで戻って、良い発声の音域を広げようとした人」ではなく、「喉が締まる発声自体をいじくって、なんとかしようとした人」がこうなる傾向が強いです。
この発声は、『声帯の内側だけを器用に締めた(固めた)発声』という感じですが、おそらくミックスボイスを感じている人は、この発声をミックスボイスだと感じている可能性が高いです。
つまり、声帯が柔軟に伸びるのが止まり(*完全に止まるわけではない)、声帯が強く硬直し出すその瞬間に『ミックスボイス』というものを感じるのではないかと。
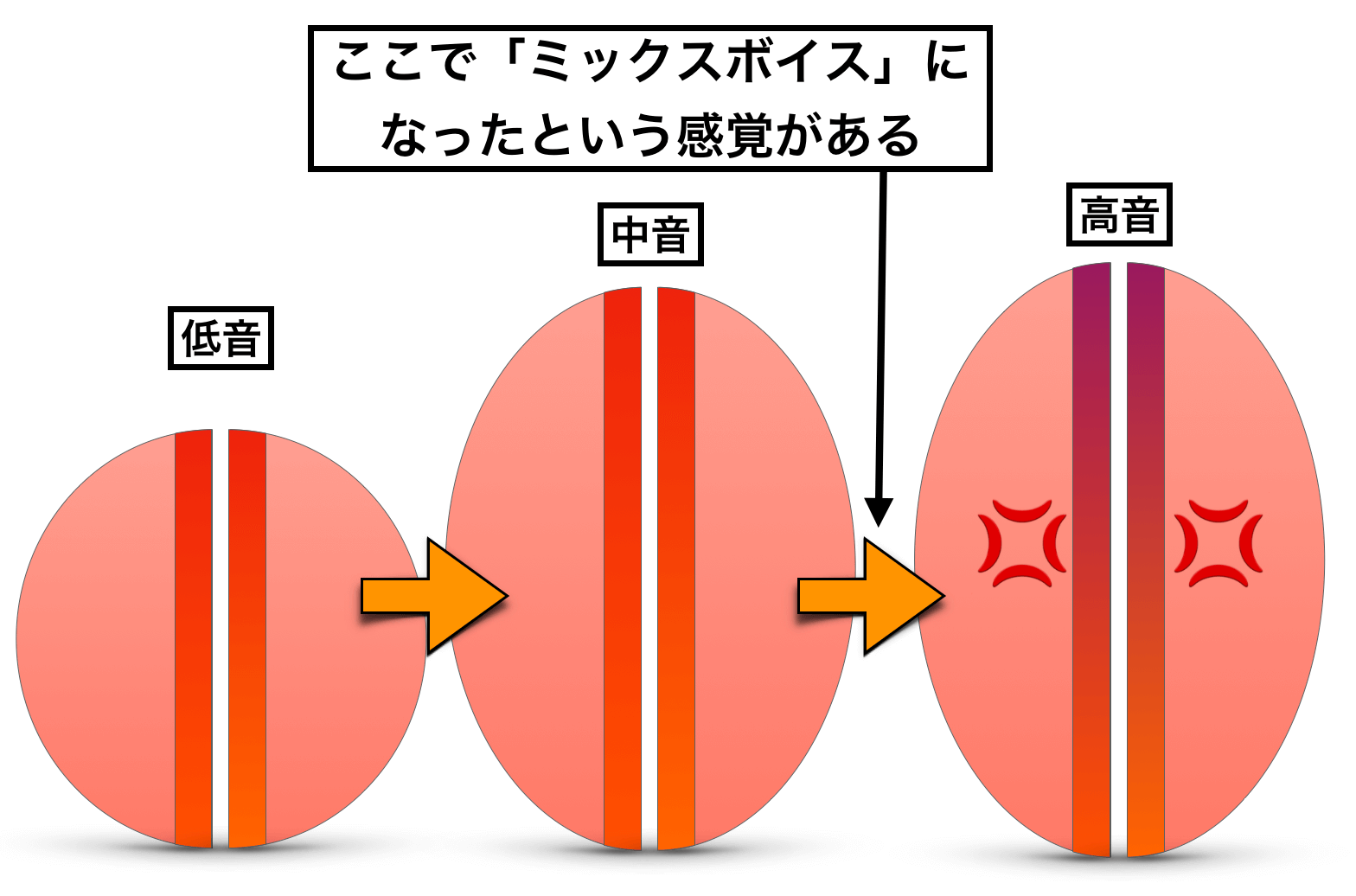
この声帯が強く硬直し出す瞬間は、感覚的に「地声から何かが切り替わった」という認識が生まれやすく、裏声でもないので、地声との間にある声区だと感じやすいでしょう。
一応声区上は「地声」になりますが、この発声を仮にミックスボイスとするのなら、
- 地声域のスムーズな声帯の伸びが止まり、声帯が上手く硬直する発声
- 声帯筋が硬く緊張する発声
という感じの定義になるでしょうか。

これによって「裏声ではない音色(地声っぽさ)」と「高音」という二つを成立させることができます。
この発声は音程的には高い声は出せます。裏声にも聞こえませんし、鍛えれば大きな声量も出せるでしょう。
しかし、
喉周りが締まっていないとは言え、声帯に余計な硬直・緊張がある発声は、歌唱上あまり良いものではない(=上手く歌えない)可能性が高いです。
この発声は、喉周りはある程度ほぐれているが、内側(声帯)に余計な硬直が残っている状態です。つまり、完全にほぐれているわけではなくベースは喉締め発声なのですね。
通常、地声の音程を上げるときはこういくべきなのに↓
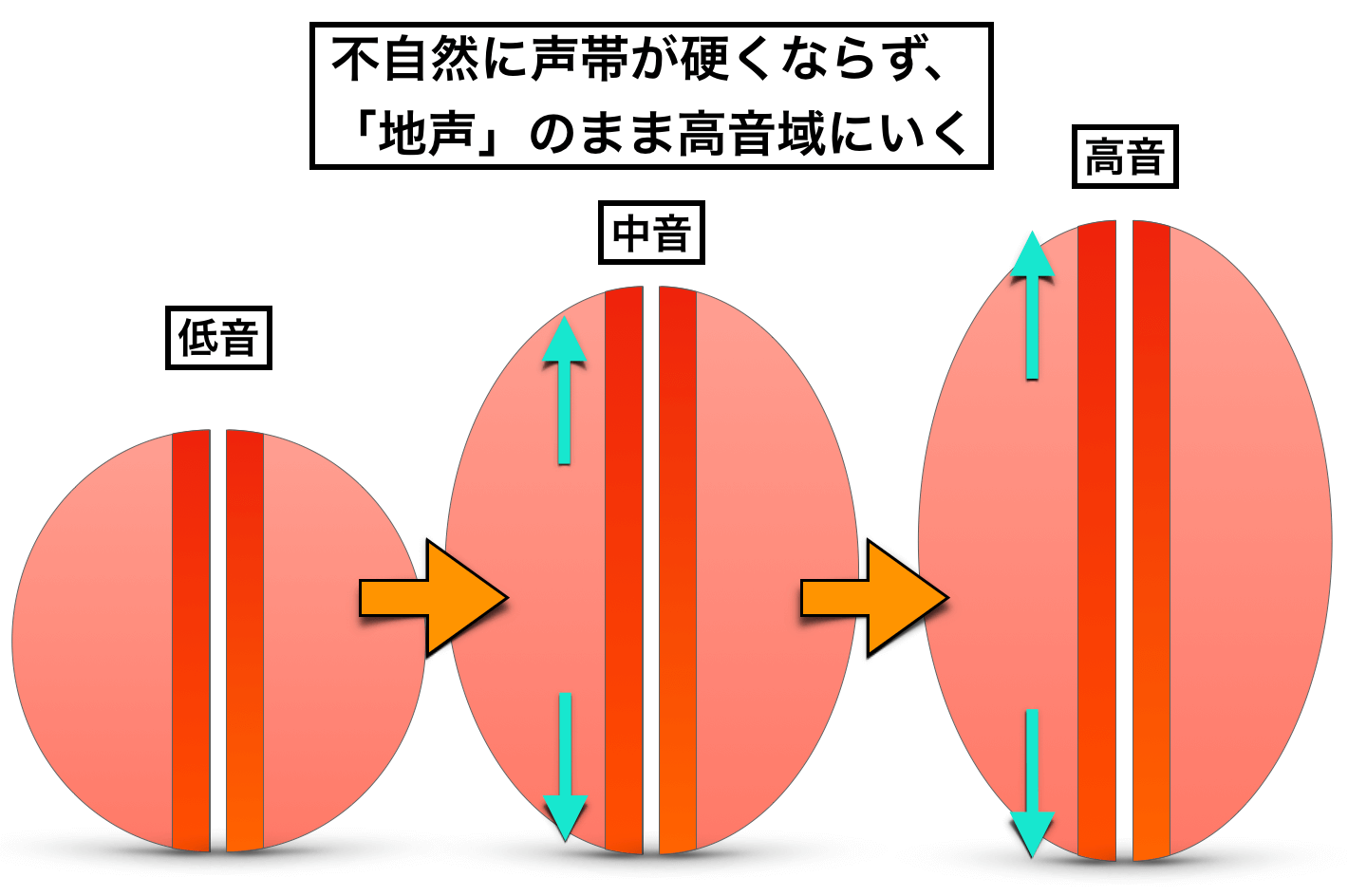
この発声では、高音を出すために声帯を固めてしまっています↓
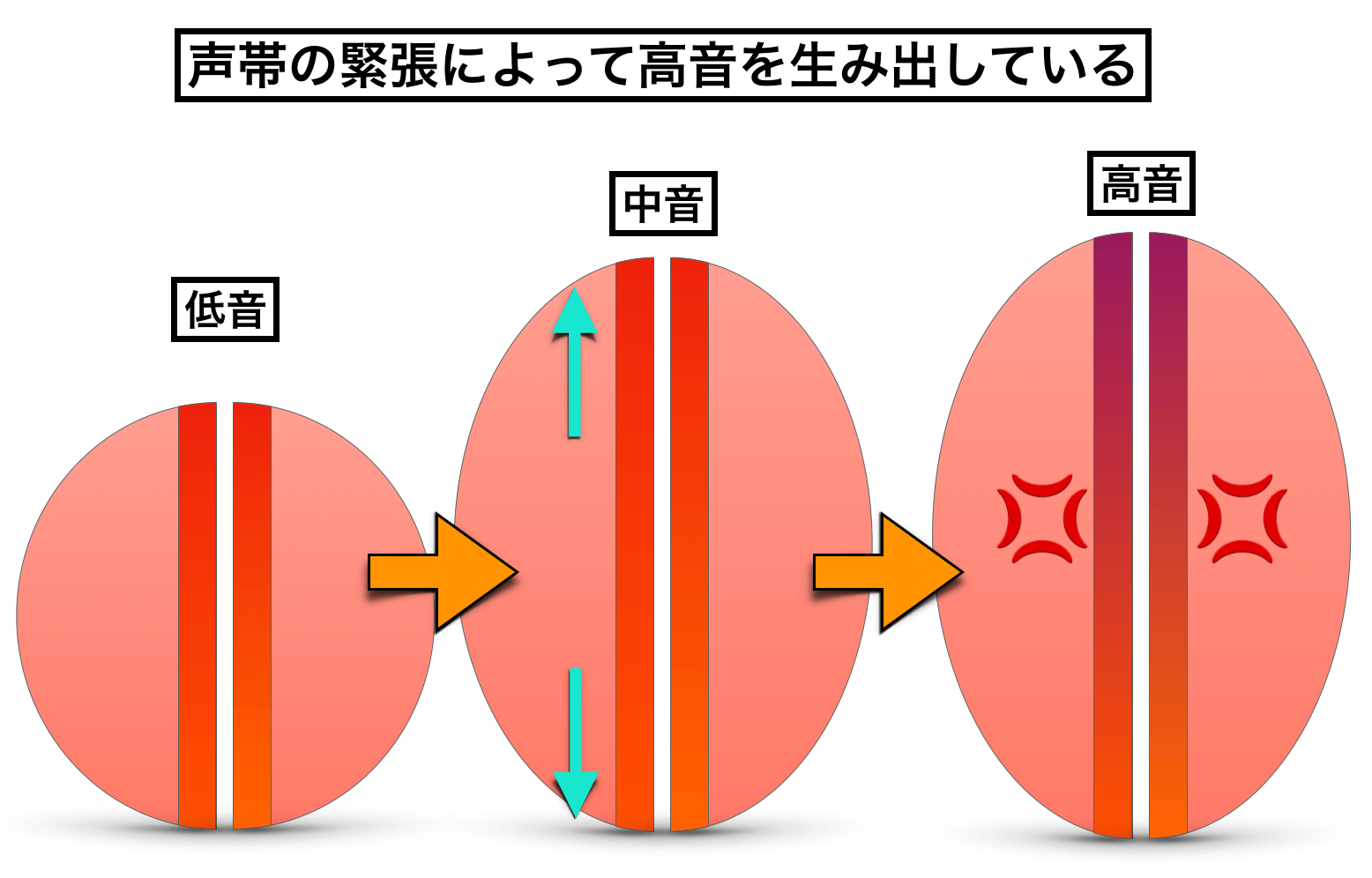
これによって、
- どこか美しい倍音が乗らない
- どこか魅力的に聴こえない
- 金属的に聴こえる
- 細く聴こえる
- 地声から薄皮一枚剥がれたような音色
- べちゃっと潰れた声に聴こえる
- 志村けんさんの声っぽくなる(いわゆる志村声)
- 音程やリズムを高度にコントロールできない
- どれだけトレーニングしても魅力的に歌えない
などなど、何らかの問題が生まれる可能性が高いです。
そういう点で、『不完全な地声』なのです。
もちろん、その発声で上手く歌えているのなら、それはそれで全く問題ありません。
歌において最も大事なことは、上手く歌えることなので、不完全だろうが何だろうが、魅力的に歌えるのなら何も問題はないのです。
しかし、こういう発声をしている人は決まり文句のように
『ミックスボイスはある程度出せるけれど、〇〇という問題がある。』
と悩みを語ることが多いです。
なぜか、すんなり自分の”ミックスボイス”の音色に満足できる人は少なく、多くの人が「高い声は出せるけれど、〇〇が問題だ。」と決まり文句のように何かしらの問題点を抱えています。
例えば、以下の動画の冒頭の発声は、まさにその例です↓
この動画は「私のミックスボイスはこのように弱く、悪い音色です。色々なトレーニングを試したけど一向に良くなりません。ミックスボイスを強くしたいけど、どうしたらいいのでしょうか?」という質問に対して、トレーナーが答えているものです。
こういう発声をしている人の多くは「ミックスボイスをもっとこうしたい、ああしたい。でも、全然良くならない。」という迷路に入っていて、長い時間さまよってしまいます。
迷路を抜け出せるのならいいのですが、なかなか抜け出せないでしょう。
なぜなら、その発声自体が余計な締まりをベースにした発声だからです。
つまり、
声帯が固まった(締まった)発声をしている時点で、間違ったルートに入っているので、その発声をどうにか鍛えて魅力的にしようと頑張っても、一向にできないのです。この発声はある意味『悪い癖』とも言えるので、一度振り出しに戻らないと、どうにもなりません。
これについては『ミックスボイスに関する悩みと改善策について』の記事に詳しくまとめています。
少し話が逸れましたが、こうなりやすい根本原因は「声帯の柔軟性が低く、早めに喉が締まったから」です。
つまり、声帯の柔軟性が高い人は、このルートに入りにくいのです。
もちろん、どれだけ柔軟性が高い人でも、音程を上げていけばいつかは喉が締まっていきますが、それが音域の後半になるので、多くの場合「そこが地声の限界」として受け入れやすいです。また、限界を開発するにしても、それまでの音域はある程度歌えるので、その音域に執着しすぎることはありません。
ところが、声帯の柔軟性が低い人は、音域の中盤に喉が締まってしまうことで、歌える曲があまりなく、その音域を無理に開発しようとします。そして、そこばかりに執着しやすいです。
そこで、地声の音域を丁寧に広げようとすれば問題ないのですが、その喉締め発声をベースにトレーニングをした場合、『声帯だけを不自然に締めた不完全な地声』を身につけやすいということです。
もう一つ、「なぜ、地声の音域を広げようとせずに、喉締め発声をベースにトレーニングしてしまう人がいるのか?」という部分ですが、これは『そこにミックスボイスがあると思っているから』でしょう。
つまり、あらかじめミックスボイスについての何らかの曖昧な知識があって、それを探すようにトレーニングすると、それっぽい発声(不完全な地声)が見つかってしまうのですね。
②自分の声帯の音域を無視している場合
これは、
- 自分の声帯における音域の限界を無視して高音域を開発すると、必然的に「不完全な地声」になる。それをミックスボイスと認識している
ということです。
例えば、『声が低い人』と『声が高い人』が高い声帯の柔軟性(同じレベル)を持っているとします。声帯の柔軟性は高いので、両者とも音域は広く、同じレベルなので音域の広さも同じです。
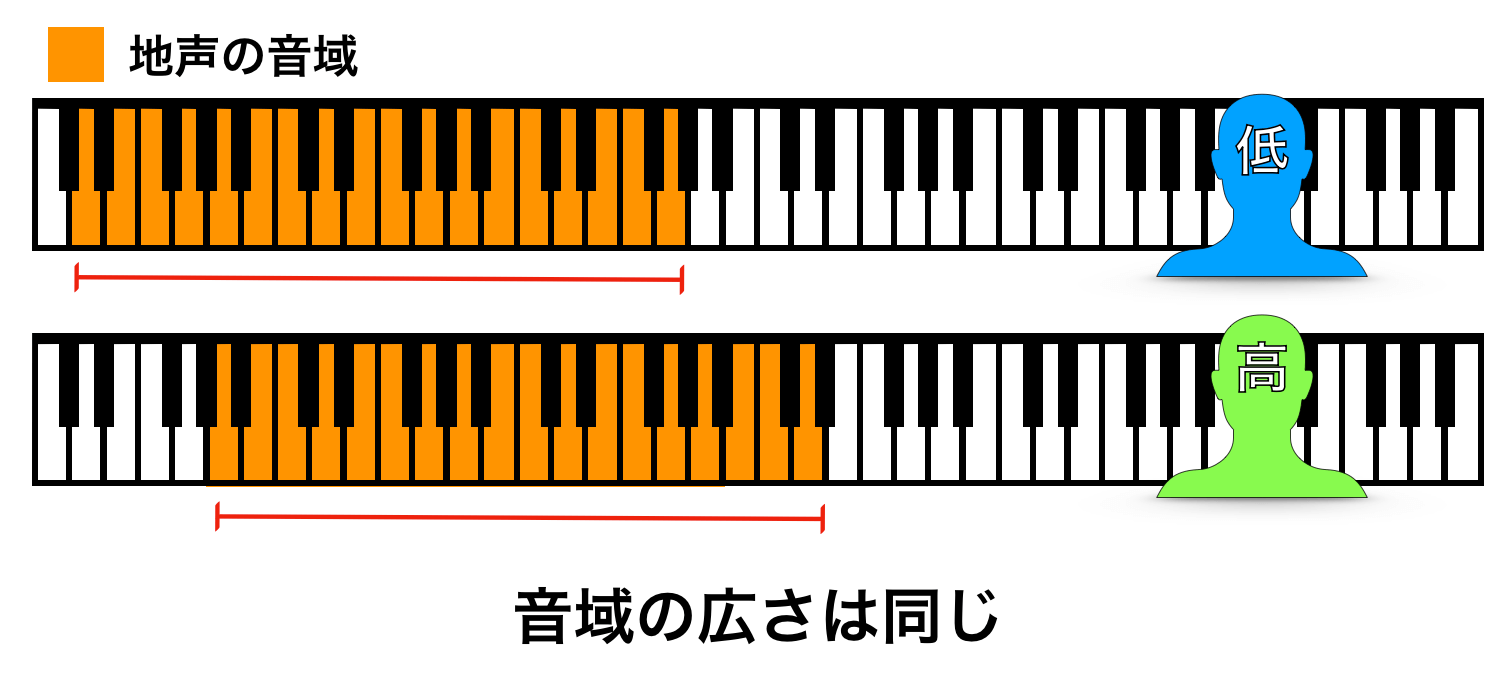
しかし、持っている声帯が違うので、その音域の位置はズレています。
ここで、声が低い人が自分の音域を無視して、無理に高い声で歌おうとします。すると、先ほどの『不完全な地声』を身につけやすくなります。それをミックスボイスだと感じているということです。
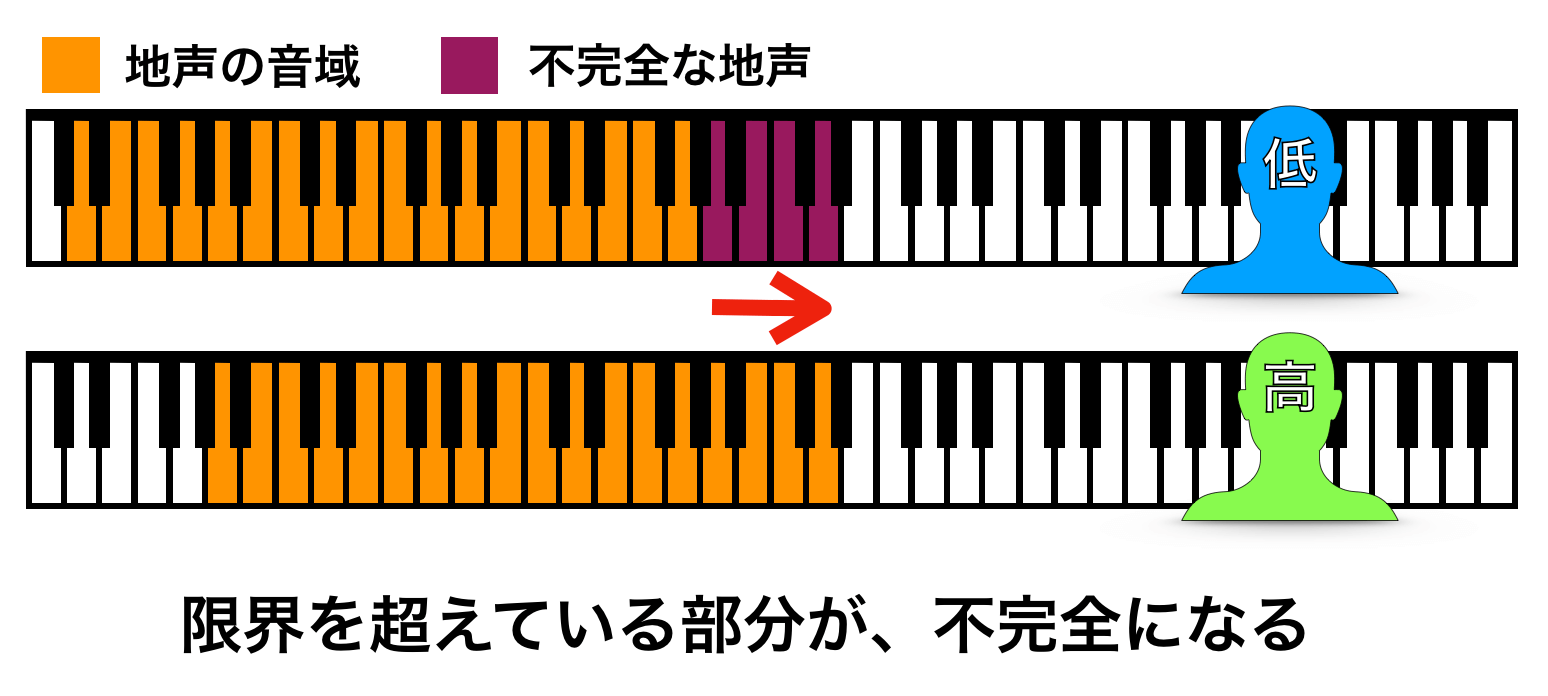
いくら柔軟性がある人でも無限に音域を上げられるわけではありません。限界を超えれば、声帯は綺麗な地声の状態を保つことができないので、こうなるのはある意味自然なことです。
声が高い人は、あまりその限界を越えようとはしない(越える必要性がない)のですが、声が低い人は無理やり限界を越えようとする人もそこそこいます。
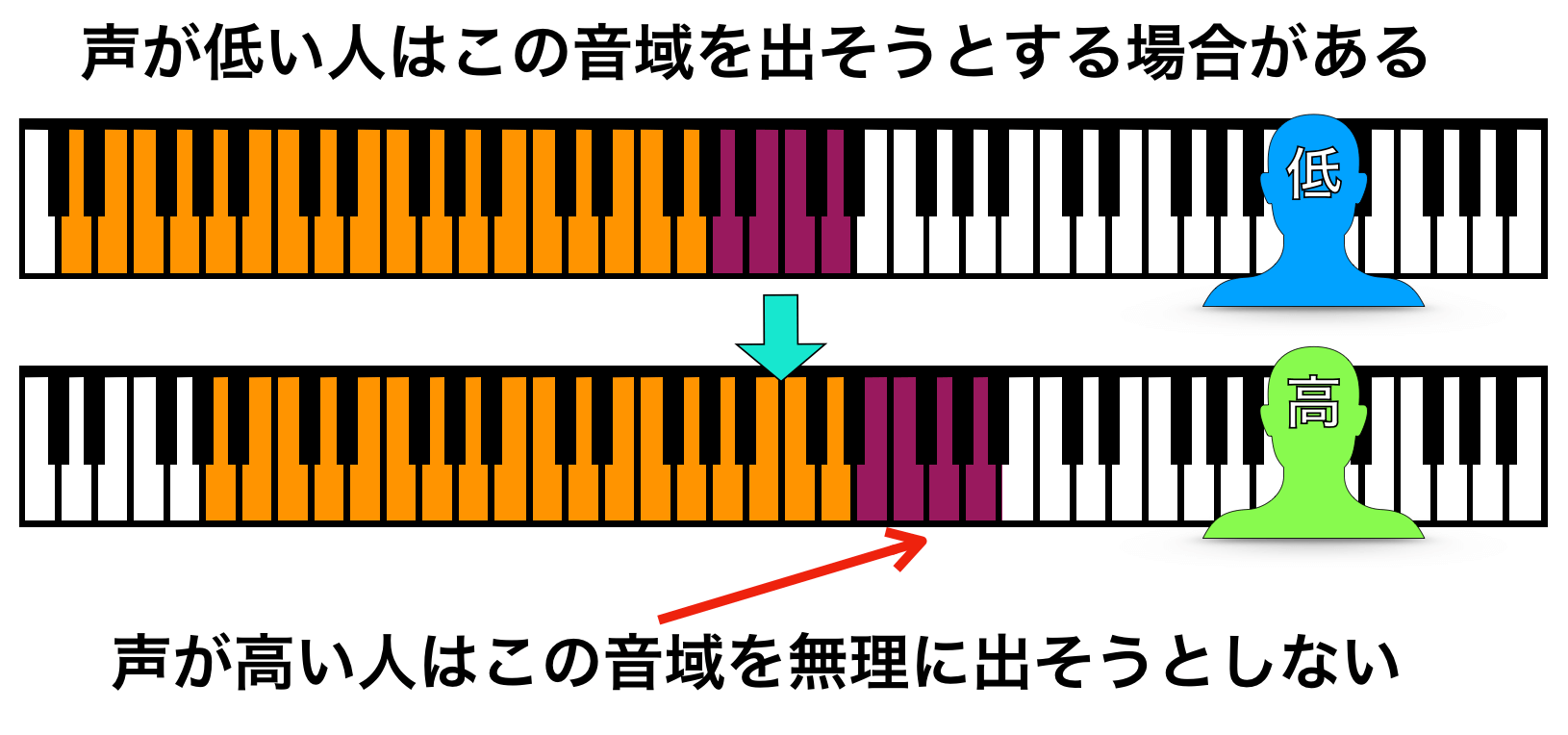
そういう点で、声が低い人の方がミックスボイスを認識しやすいということです。
ただし、声帯の柔軟性がある人の「不完全な地声」は、歌の一部でスパイス的に使うなどであれば、有効に使えることもあります。なので、場合によっては問題のない発声とも言えますが、いくら声帯の柔軟性があろうと「不完全な地声」だけで歌えば、やはり聞き苦しい歌になるでしょう。
また、「不完全な地声」をたくさん使っていると、健全な地声域を侵食してしまう可能性もあるという点に注意が必要です。

とにかく、通常の地声域の限界を超えれば、誰もが喉や声帯は締まっていく。そして、上手く喉周りの締まりを解消したとしても、声帯に余計な締まりが残った「不完全な地声」になってしまう。
なので、自分の声帯の音域を無視した人は、ミックスボイスを認識しやすいということです。
人は自分に合う”ミックスボイス”の概念を作っている
長くなったので、上記までの8つを再度まとめておきます。
- 地声と裏声を滑らかに繋げられる状態(声区融合)
- 地声と裏声を感覚的に混ぜる発声
- 地声の高音発声
- 裏声の低音発声
- 地声と裏声の中間的な声質の発声
- 共鳴位置が中間にある地声
- 共鳴位置が中間にある裏声
- 地声と裏声の間を埋める発声方法(=間にある声区)
他にもあるかもしれませんが、これだけの考え方のパターンがあり、人によって(流派によって)定義が違います。
これだけ違うと、調べれば調べるほどに、何が本当で何が嘘かわからなくなってしまいます。
なので
ミックスボイスというものは最終的に、人それぞれが自分にとって納得できる都合のいい解釈をして、『自分にとってのミックスボイス』という概念を上手く作り上げていると言えます。

ミックスボイスという概念・認識・感覚が理解できない人は「ミックスボイスはない」とするでしょう。
それが「ある」とする人は、自分の喉・声帯・感覚・意識に基づいた上で、色々な情報を取捨選択して「ミックスボイス=〇〇」という自分が腑に落ちる落とし所を見つけていることでしょう。
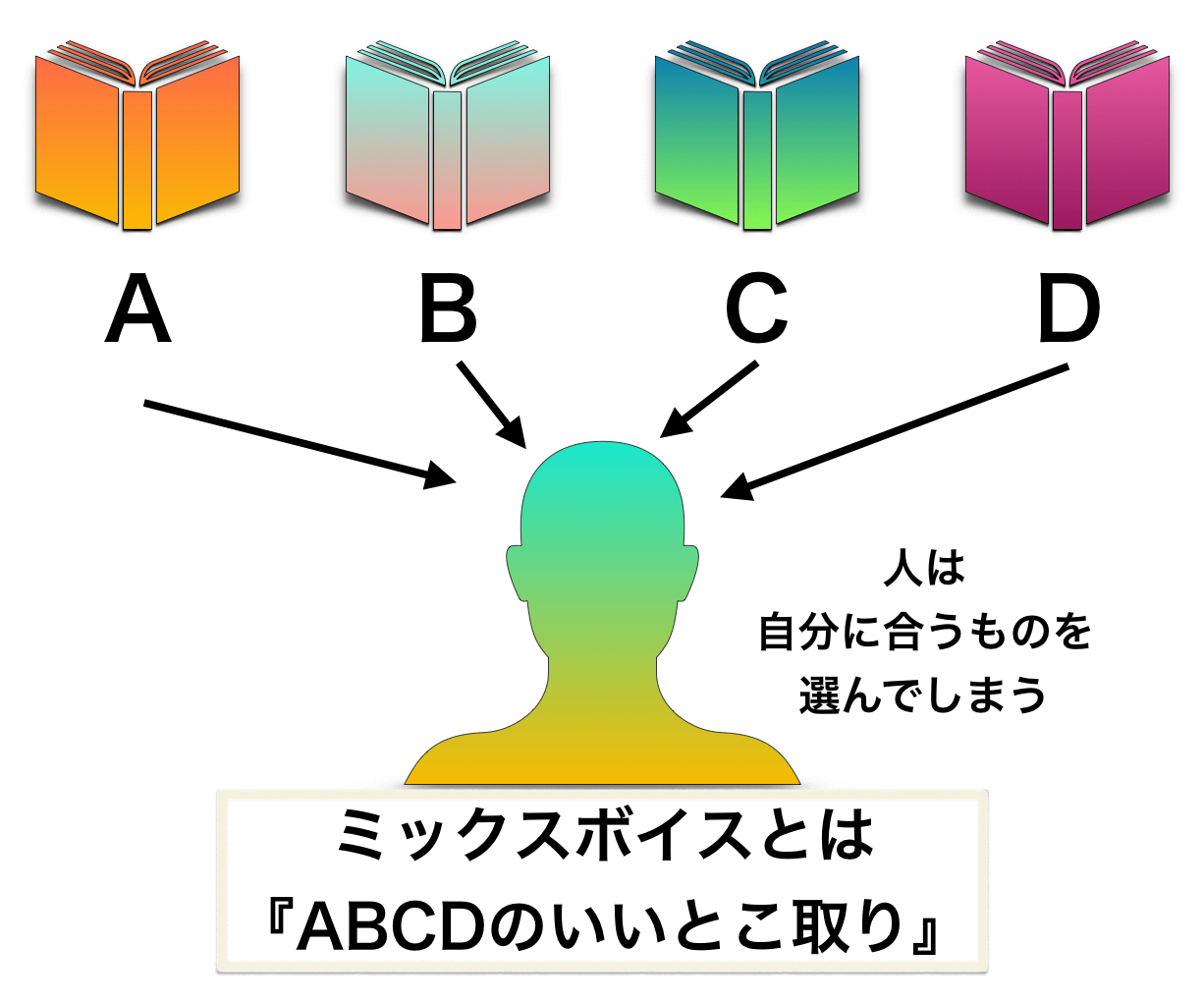
こうして、人それぞれが自分に合う解釈を続けているので、収拾がつかない言葉になっているのですね。
ミックスボイスという言葉を使う時は、定義のすり合わせが必須
ここまで色々な解釈がある言葉なので、もしミックスボイスという言葉を使って指導を受けたり、会話したりする時には、その定義を完璧にすり合わせる必要があります。
そうしないと、
- 発信者「ミックスボイス(声区融合)っていうのは、これをこうすればできるよ。」
- 受け手「なるほど。ミックスボイス(地声のような高音発声)はこうすればいいのか。」
などの誤解が生じやすいのですね。
なので、『ミックスボイスは人によって違う』ということを前提に、この言葉を聞いたり、使ったりしなければいけないということです。
例えば、プロのシンガーがミックスボイスを語っている場合、『この人にとってのミックスボイスは一体何を意味しているのか?』を徹底的に追求しましょう。
いくつか参考例を貼っておきます(*再生位置27:03〜「どこがミックスボイスか?」、30:04〜「ミックスボイスの感覚の比について」)↓
(*再生位置38:10〜)↓
おそらく、ある程度「このことをミックスボイスと言っているのかな?」と予想はできるものの、はっきりと言い切れないという感じになると思います。
こういうものは、目の前でその詳細をアレコレ聞けるわけではないので、はっきりしないことの方が多いです(*だからこそ、定義が増えていく)。
何ならボイストレーナーが語っているものでさえ、はっきりしないこともあるでしょう。
しかし、はっきりしないからと言って、こちらの主観で決め打ちするのは危険です。はっきりしない時は、『はっきりするまで参考にしない』がベストだと思います。
プロのシンガーでもミックスボイスという概念が無い人は多い
先ほどのように「ミックスボイス」について語るシンガーもいますが、意外と多くのプロのシンガーは「ミックスボイス」というものを語りません。
割合としては、語っている人の方がはるかに少ないと考えられます。
SNSやYOUTUBEの発展により、世界中のプロのシンガーたちがその歌声について直接発信する機会がかなり増えましたが、意外とミックスボイスという言葉は出てこないのです。(*再生位置から「③頭声」と「④地声」について)↓
先ほどのジェシー・Jさんの動画も同じでしたね。
この理由は、認識できないからです。
つまり、歌っている中にミックスボイスという体感がないので、それを理解できないし、知ろうともしない(知る必要がない)のですね。
あとミックスボイスことよくわかっていないのでミックスボイスという単語を見る度にミックスジュースが頭に過ぎります
— Ado (@ado1024imokenp) July 12, 2020
こういう人は結構います。
仮に、ミックスボイスという言葉は知っていたとしても、そう深く考えていない人や、「人からよくミックスボイスと言われる。よく分からないけど、そうなんだろうな。」と、他人から言われたからそう思い込んでいるという人などもいます。
実際、先ほどのASKAさんの動画でも、40:02〜「ミックスボイスなんて言葉は知らなかった。」とおっしゃっています。
つまり、
ミックスボイスという感覚や概念を知らなくても歌は歌えるし、上手くなれるということです。
そもそも、「ミックスボイス」という用語が普及し始めたのは、1990年代頃〜と言われています。
それ以前は、そんな用語や概念は一般人はもちろん、歌手ですら知らない言葉だったのです。しかし、1990年代以前にも世界中にすごいシンガーはたくさんいましたから、その言葉が必ずしも歌に必要だとは言えないのですね。
結局、どう考えるのがベストか
まず、ミックスボイスの定義については『みんな違ってみんな良い』で済ませておくのが一番良いのではないかと思います。
ミックスボイスが『ある人』も『ない人』もそれでOK。人それぞれの定義や概念の違いもあってOK。どう考えようが人の自由です。
ただし、どう考えるにしても、必ず押さえるべきポイントがあります。
それは、
『自分の歌の成長にとって、得なのか、損なのか』という点です。
例えば、
- ミックスボイスを追い求めた結果、不自然な癖のついた発声を身につけてしまい、いくら練習しても上手く歌えない状態になった
という人がいたとします。
この人は、そのミックスボイスがどんな定義であれ、ミックスボイスを考えたことで結果的に『損』をしていますね。つまり、ミックスボイスのことなんて一切考えない方が『得』だったと言えます。
他にも、
- ミックスボイスを追い求めた結果、歌が上手くなることができた
という人がいたとします。
この人は、ミックスボイスのことを考えたことで『損』をしていません。それがどんな定義であれ、結果的に歌が上手くなれたのなら『得』だと言えるでしょう。
他にも、
- ミックスボイスを追い求めた結果、色々な本やボイストレーナーの言っていることがあべこべで、あっちこっちと迷走してたくさんの時間を無駄にしてしまった
という人。
これは経験値や知識を広げるという点では『得』とも言えるかもしれませんが、時間的には『損』ですよね。この辺りの損得勘定は、人それぞれの考え方によって変わってくるかもしれませんが、成長の観点では『損』側に感じる人が多いでしょう。
このように、自分の歌の成長にとって『得なのか、損なのか』という基準で、ミックスボイスをどう考えるべきか決めましょう。
判断できない場合、「ない」ものとしておけばいい
「自分では判断できない」という人もいると思います。
そういう人は、
ミックスボイスのことを深く考えない=「ない」ものとしておく
というのがおすすめです。
その理由は、歌の成長においては損をする可能性がほぼないからです。
歌が上手くなることにおいては、ミックスボイスという言葉を知らなくても一切問題ないと言えます。先ほども述べましたが、1990年代以前にはそんな言葉は普及していなかったのですから。
逆に、ミックスボイスという言葉を追いかけることで、何らかの損をする可能性が上がります。少しでも迷えばそれだけ時間の無駄ですし、迷って間違ったルートに入ると大きな損になってしまいます。
もちろん、損をしない可能性もありますが、リスクが上がる選択であることは間違いありません。
であれば、最も無難な選択は『ミックスボイスなんて気にしないこと』になるということです。
あくまでも「歌の成長においては」のお話なので、それ以外の目的であればまた話は変わるのですが、ほとんどの人にとってはそれ以外の目的はないでしょう。




